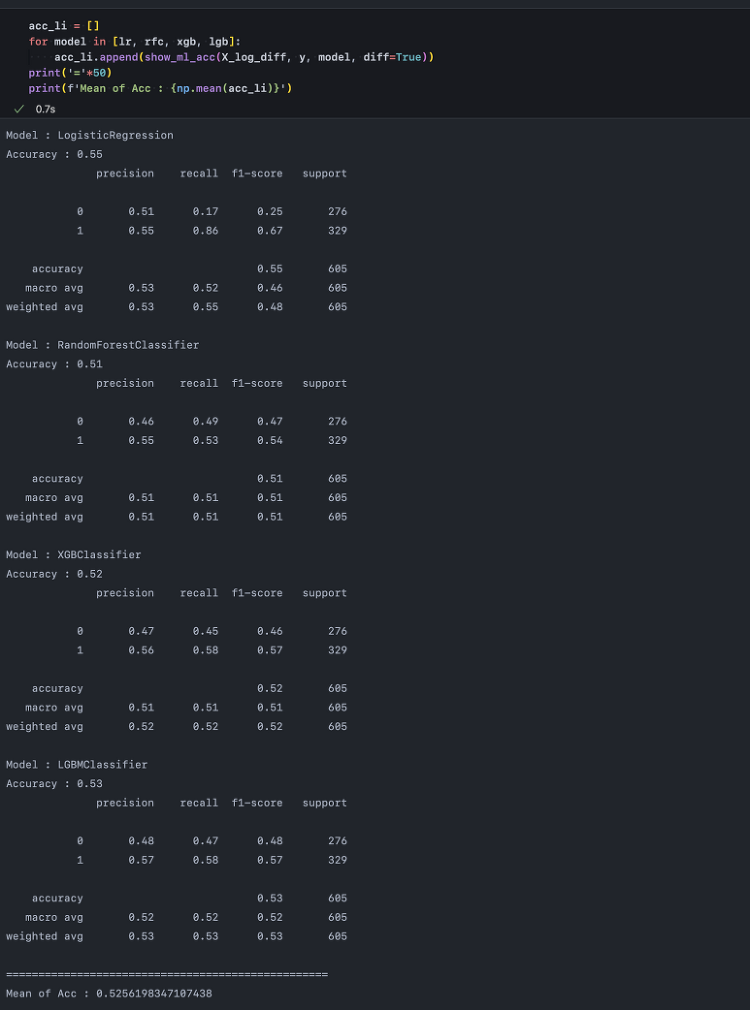
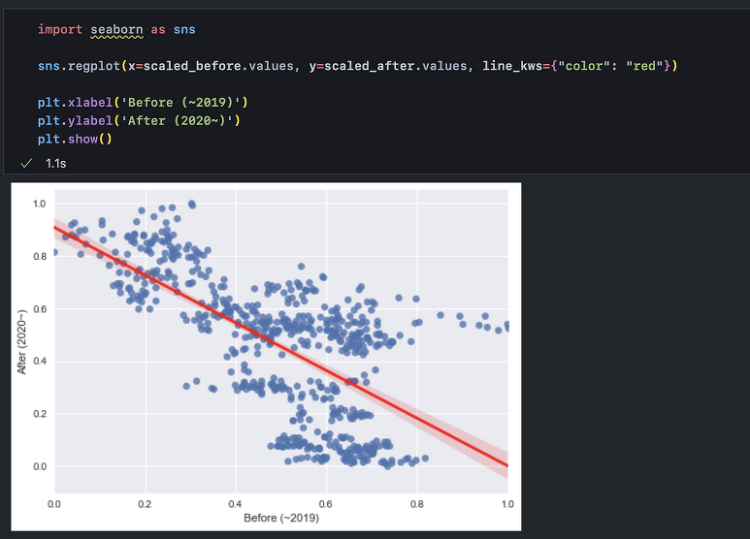
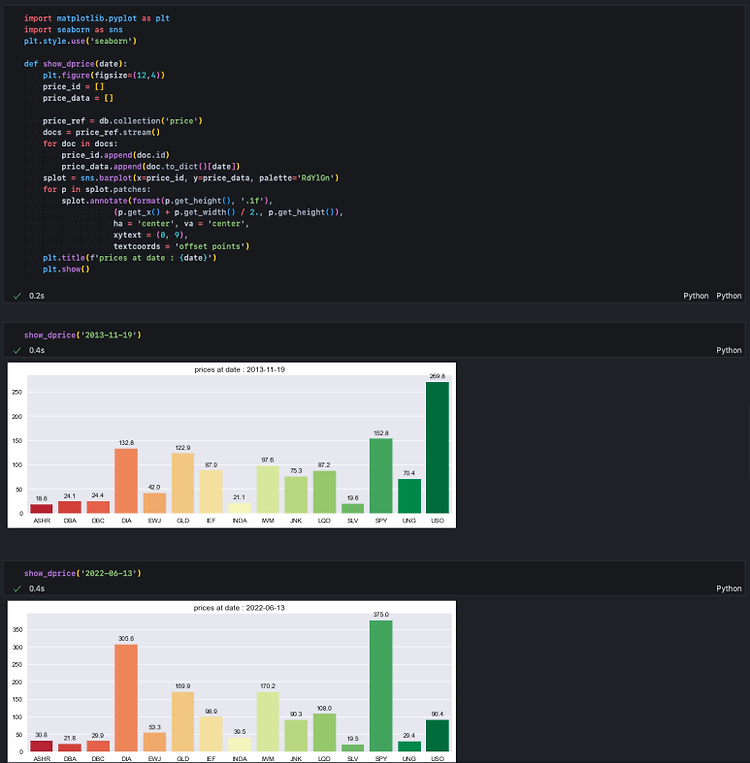
데이터를 시각화하는 도구는 여러 가지가 있습니다. 특히 시계열 데이터의 경우 엑셀이나 스프레드시트, PPT만으로도 충분히 의도하는 내용을 차트로 만들어낼 수 있습니다. 따라서 '굳이' 파이썬으로 시각화를 하고자 한다면 단순히 파이썬으로 분석, 시각화까지 이어서 진행할 수 있는 연속성 외에도 파이썬이 주는 자유도와 자동화로 인한 편의를 충분히 활용해야 합니다. 파이썬을 사용하면 반복문과 함수를 손쉽게 활용하고, 프로그래밍을 통해 여러 차트를 동시에 그려낼 수 있습니다. 이를 극대화해주는 함수가 subplots()입니다. Step 1. 레이아웃 설정 먼저, matplotlib.pyplot 패키지를 plt라는 이름(alias, 별칭)으로 불러옵니다. plt를 통해 아래와 같이 전체 레이아웃을 subplot..