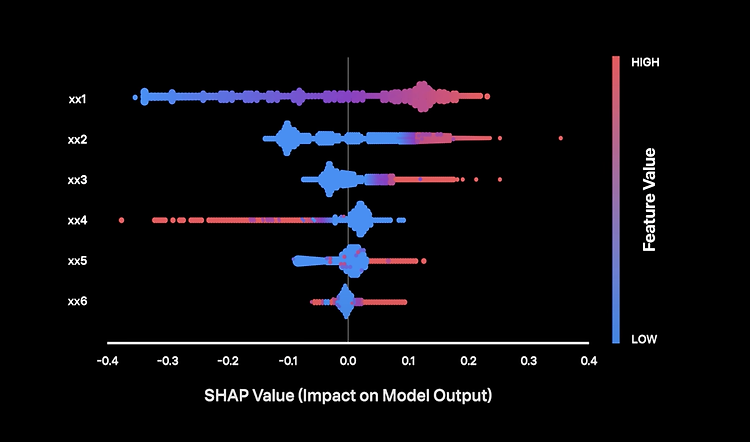
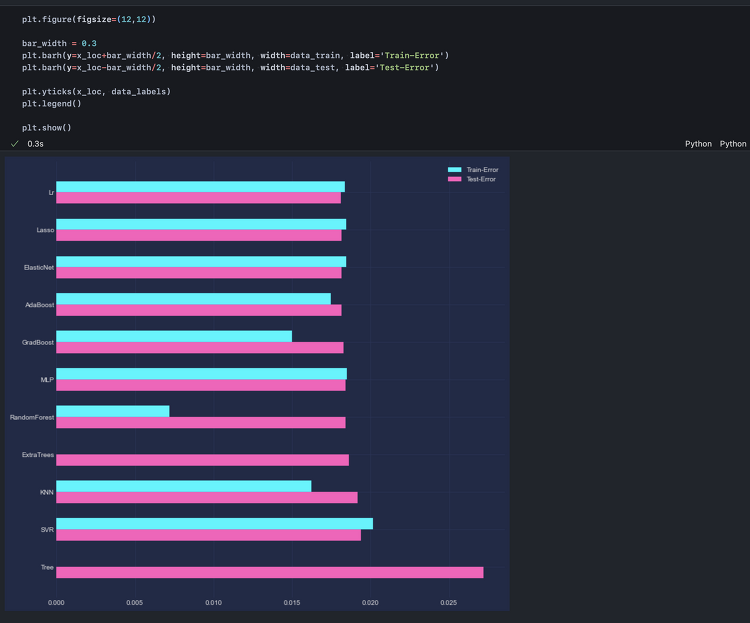
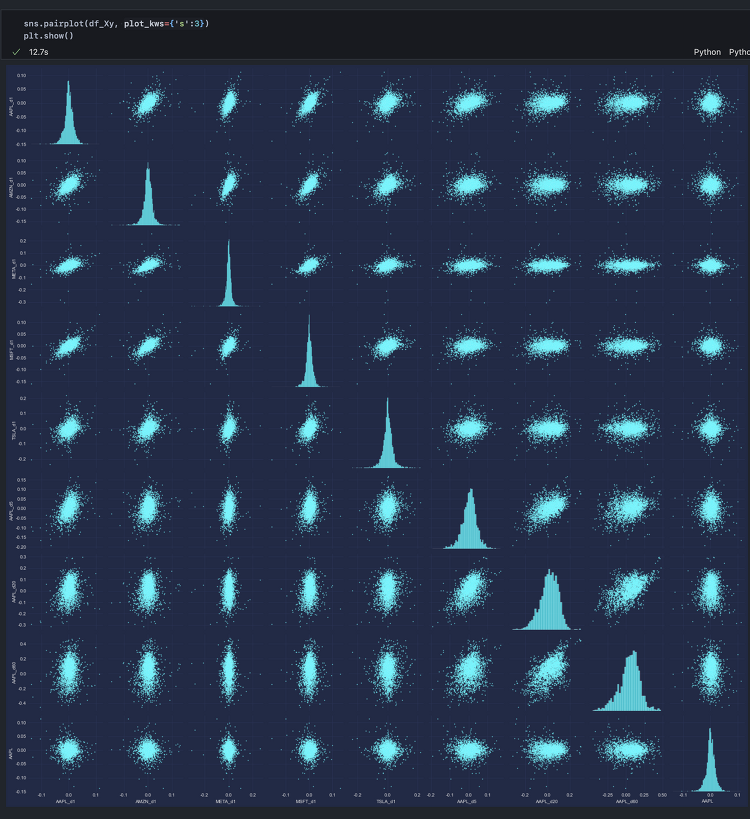
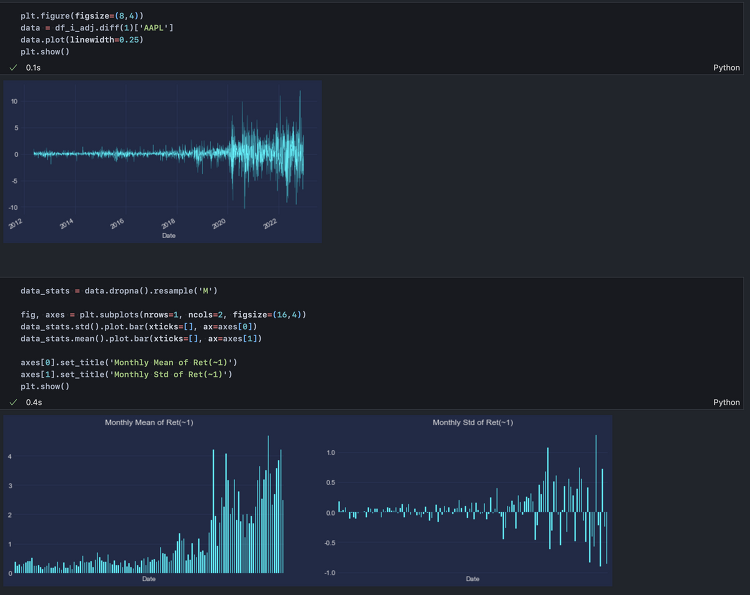
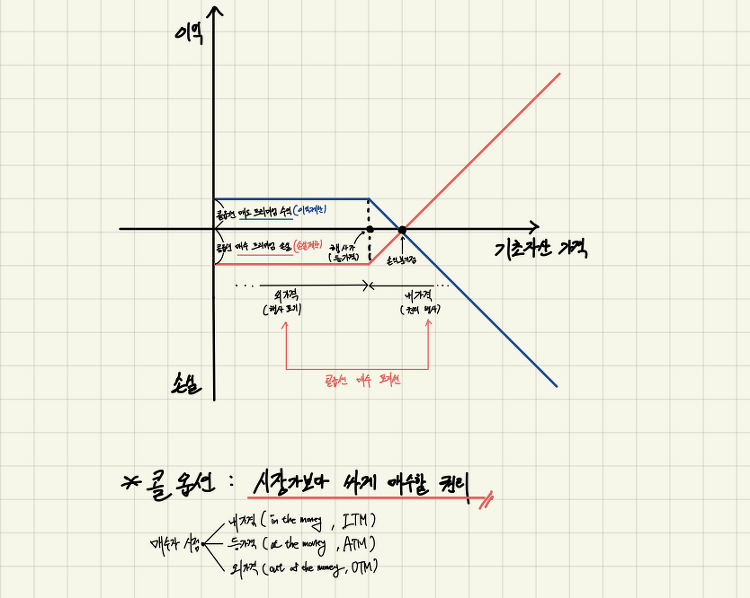
2025년 세계 경제는 중요한 기로에 서 있다. 국가 경제의 핵심 지표 중 하나는 바로 부채 사이클이다. 미국의 부채 수준, 이자 지급액, 그리고 통화량(M0, M1, M2)을 분석함으로써 경기 침체 리스크를 이해하고, 이에 따라 적절한 경제 전략을 수립할 수 있다.본 글에서는 미국 부채 사이클을 기반으로 현 시점 경제 상황을 분석하고, 통화량을 고려해 2025년 경기 침체 리스크를 평가한다.Step 1. 데이터 수집부채 사이클과 경기 침체 리스크 간의 관계를 이해하기 위해 Federal Reserve Economic Data(FRED) API에서 데이터를 수집한다. 다음과 같은 변수를 포함하도록 한다.이자 지급액(Interest Payments)국내총생산(GDP)연방 부채(Federal Debt)통화기..