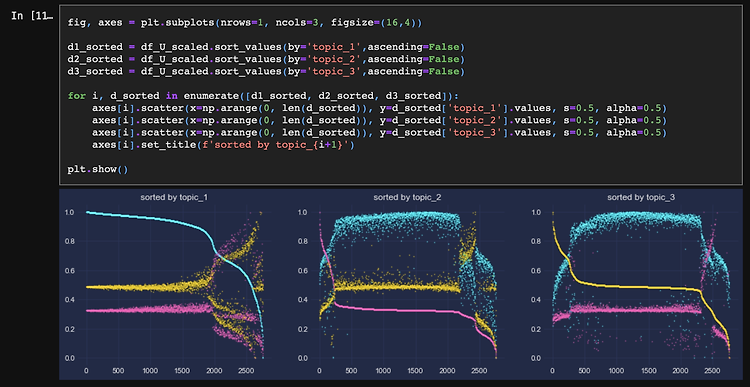
Step 1. 토픽모델링이란 토픽모델링은 특정 문서의 확률적 카테고리를 나누는 비지도학습 방법론이며 기본적인 컨셉은 다음과 같다. 문서는 단어의 조합이다. 문서 내 함께 등장하는 단어는 서로 연관성이 있다. 모든 문서에서 자주 등장하는 단어는 특수한 의미를 내포하지 않는다. 반면, 그렇지 않은 단어는 특수한 의미를 내포한다. 즉, 모든 문서에서 자주 등장하지 않으면서 특정 단어들과 함께 등장하는 단어들은 서로 유사한 의미를 내포한다. 그러므로 단어의 조합인 문서는 의미가 있는 단어들의 비중에 따라 카테고리(Topic)가 결정된다. 우리는 이러한 컨셉의 프로세스에 따라 1.문서를 단어 조합으로 가공하고, 2~5.문서 내 각 단어들의 의미를 부여한 다음, 6.문서의 토픽을 결정해보도록 하자. Step 2. ..