Step 0. 파이프라인
Elastic Stack은 Elastic Search를 중심으로 Beats, Logstash, Kibana를 활용해 데이터 파이프라인을 구축하는 일련의 설계 방식이다. 파이프라인의 구성은 다음과 같다.
구성 :
- Beats : 데이터 수집 및 전송
- Logstash : 데이터 전처리(필터링)
- Elasticsearch : 데이터 저장 및 관리
- Kibana : 데이터 시각화
다음은 파이프라인의 동작 방식이다.
동작 :
- Yahoo Finance에서 각 주요 국가의 시장지수와 금, 은, 유가 등의 각종 매크로 데이터를 추출한다.
- 추출한 데이터를 Beats로 읽어들여 Logstash로 보내 문자열 처리를 거친 다음,
- Elastic search로 적재하고,
- Kibana로 대시보드를 그린다.
먼저, 현재 작업 환경은 아래와 같다. 무거운 실습이 아니므로 동일하게 세팅할 필요는 없으나 버전 등에 이슈가 있을 수는 있다.
작업 환경 :
- Macbook Pro 2019 - i9, 16GB
- GCP 가상 머신 4대 할당(e2-small 3대 + e2-medium 1대)
- 가상 머신 1대에 클러스터 1개 배치(클러스터 당 노드도 1개씩)
- filebeat 설치(Local)
- logstash 설치(Local)
- elastic search 설치(e2-small 3개 각각 설치)
- kibana 설치(e2-medium 1대에 설치)
- filebeat, logstash, elastic search, kibana 모두 7.11 버전 통일
Step 1. Yahoo Finance 데이터 수집
Yahoo Finance에서 종가 데이터를 수집할 것이다. 한 번의 요청으로 최대한 많은 데이터를 가져오기 위해 브라우저 네트워크 탭의 XHR 정보를 사용한다. 서버에 직접 데이터를 요청하는 것으로, url 파라미터를 수정해가며 최대 기간의 일 단위 가격 정보를 수집할 수 있다. 헤더와 url를 살펴보고, period 등 수정 가능한 구간들을 확인한다.

requests 패키지를 통해 데이터를 불러올 것이다. 데이터는 json 형태로 반환되므로 적절한 가공이 필요하다. 아래와 같이 클래스를 구성하면 여러 티커를 순차적으로 요청하면서 하나의 데이터 테이블에 적재할 수 있다.
활용할 수 있는 총 15개의 국제 매크로 지수들을 티커 목록에 넣고, 위에서 만든 클래스를 통해 한 번에 데이터를 불러온다.
데이터 타입을 확인하고, csv 파일로 저장한다. 이 파일을 beats가 한 줄씩 읽으면서 logstash에 데이터를 전송하게 된다.
Step 2. 엘라스틱 서치, 키바나 실행
현재 GCP 가상머신 4개를 사용했다. 가상머신 3개로 엘라스틱 서치 노드 3개를 구성하고 각 노드는 모두 서로 다른 클러스터를 형성한다. 첫 번째 엘라스틱 서치 서버를 메인 클러스터로 나머지 2개 클러스터가 연결되는 방식이다. 지금은 대용량 데이터에 대한 검색 실습이 아니기 때문에 엘라스틱 서치는 개인 로컬에 1대만 설치해서 띄워도 무관하며 동일한 환경을 구성할 필요는 없다.
아래 이미지는 키바나를 실행한 모습, 메인 노드에 curl 명령어로 연결된 노드 정보를 검색하는 모습이다.
키바나가 실행되면 포트 정보가 출력된다. 키바나 외부 접속 IP와 함께 포트 번호를 브라우저 url로 검색하면 키바나 어드민 페이지가 나온다.
Step 3. Beats 설정
이제 수집한 데이터 파일을 beats가 인식할 수 있도록 yml 파일을 수정해 준다. Filebeat inputs 부분의 paths에 데이터 파일이 있는 경로를 작성해 주면 되겠다.
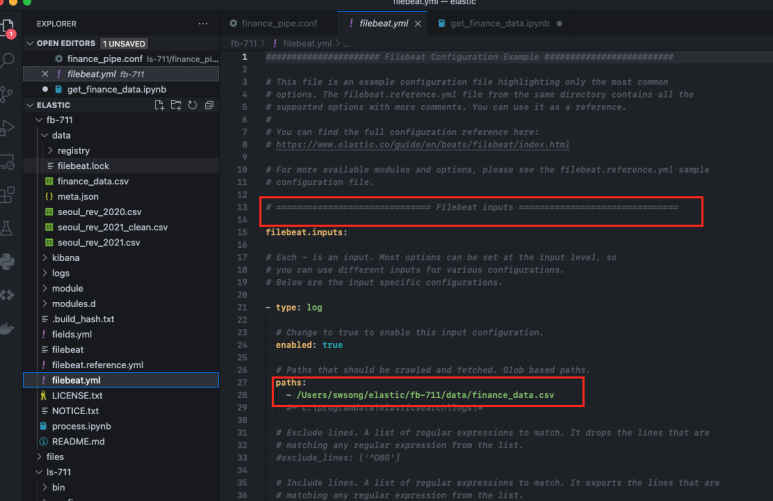
다음으로 output을 정의해 준다. beats가 데이터를 받아서 logstash로 전달해야 하므로, logstash가 실행될 로컬 port 번호를 입력해 준다.
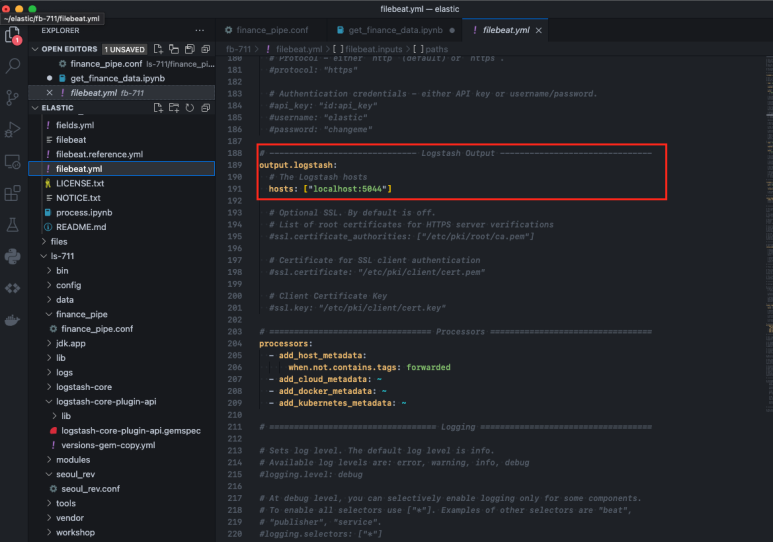
Step 4. Logstash 설정
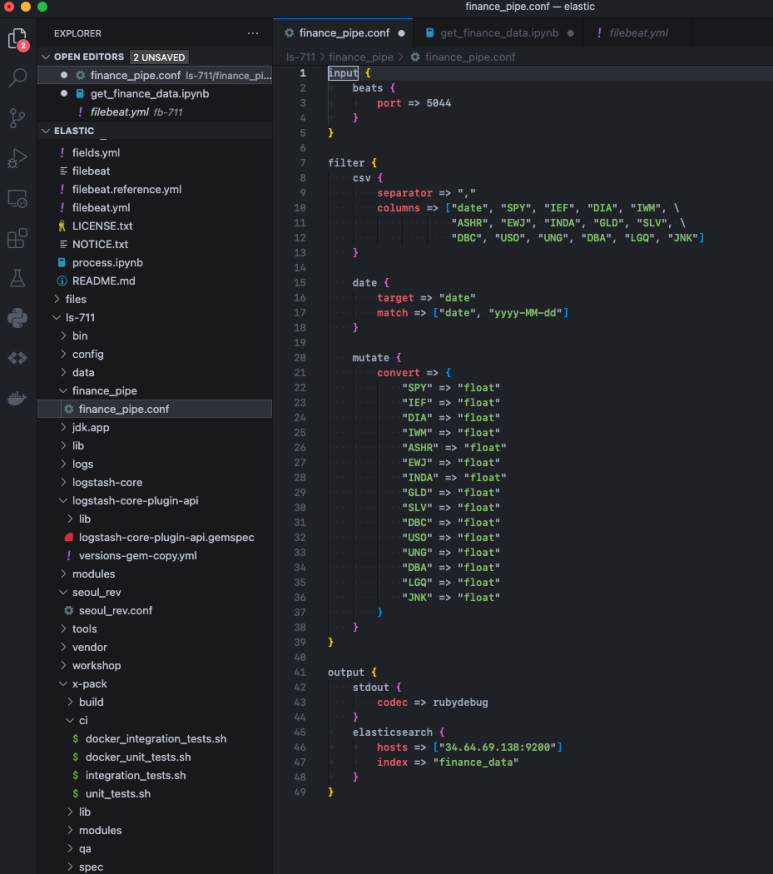
logstash도 beats와 마찬가지로 input과 output을 정의해 줘야 한다. input은 beats가 보낼 데이터가 들어올 포트 번호를 작성해 주고, output은 표준 출력(stdout)과 elasticsearch 외부 url 주소를 작성해 준다. 이렇게 하면 beats와 logstash, logstash와 elasticsearch가 하나의 파이프라인으로 연결되고, 데이터가 들어가는 과정을 표준 출력(stdout)으로 확인할 수 있다.
input, output 중간에 filter라는 것이 있다. 우리는 csv 파일 정보를 전달하기 때문에 csv 파일이라는 것을 알려주고, 칼럼을 정의해 줘야 한다. 또한 모든 데이터가 문자열 형태로 전송되므로 각 칼럼별 데이터 타입을 실수형(float)으로 변경해 줄 필요가 있다. logstash는 이렇게 데이터 전처리 역할도 수행할 수 있기 때문에 미리 필터를 잘 설계해두면 데이터가 도착하는 지점인 elastic search에서의 수고를 덜 수 있다.
Step 5. 데이터 전송
이제 beats를 실행해서 logstash를 거쳐, elastic search로 데이터를 보내보겠습니다. 데이터가 잘 넘어갈 수 있도록 elastic search와 logstash는 미리 실행되어 있어야 한다.
elastic search는 ./bin/elasticsearch로 실행해 주고, logstash는 ./bin/logstash -f (conf 파일)로 실행한다.
나의 경우, 맨 좌측 3개는 elastic search 원격 서버가 실행되고 있고, 중앙 상단에 kibana 원격 서버가 실행되고 있다. 그리고 맨 우측 하단에 위 명령어를 통해 logstash가 실행되고 있으며, 마지막으로 맨 우측 상단에 filebeat을 실행하는 모습이다. filebeat도 logstash처럼 실행할 때 설정 파일(yml)을 지정해 준다.
참고로, beats는 데이터를 한번 읽어들일 때마다 로그가 기록되고, 그다음 데이터를 가리킨다. 따라서 전체 데이터를 다시 전달하고 싶다면 저처럼 rm -rf data/registry/* 명령을 실행해 주시면 되겠다.
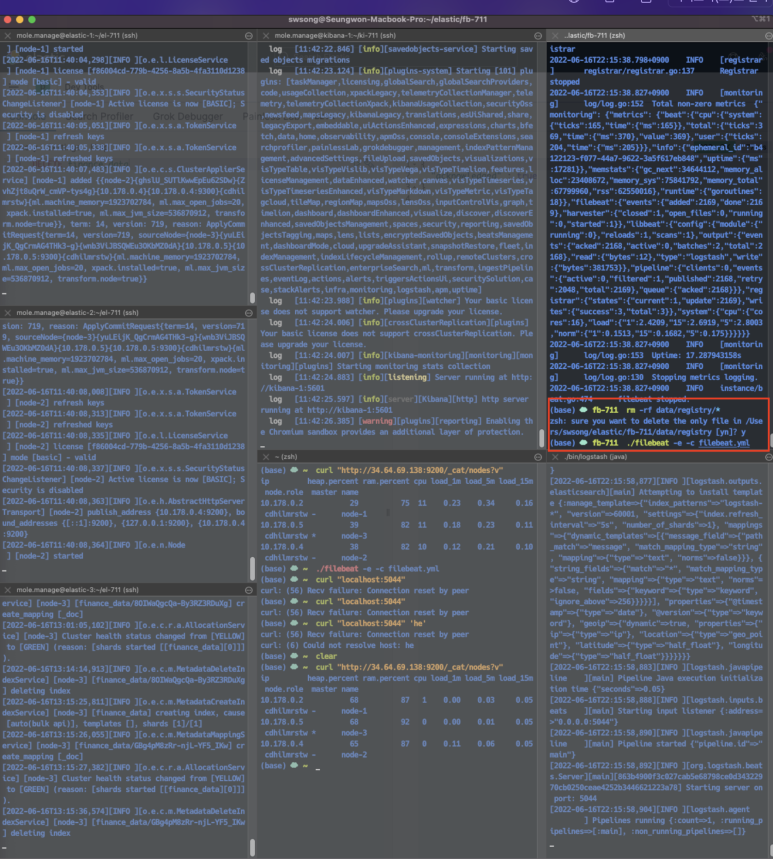
정상적으로 파이프라인이 동작하면, 다음과 같이 logstash 모니터링 화면에 표준 출력으로 데이터가 넘어가는 모습을 볼 수 있다.
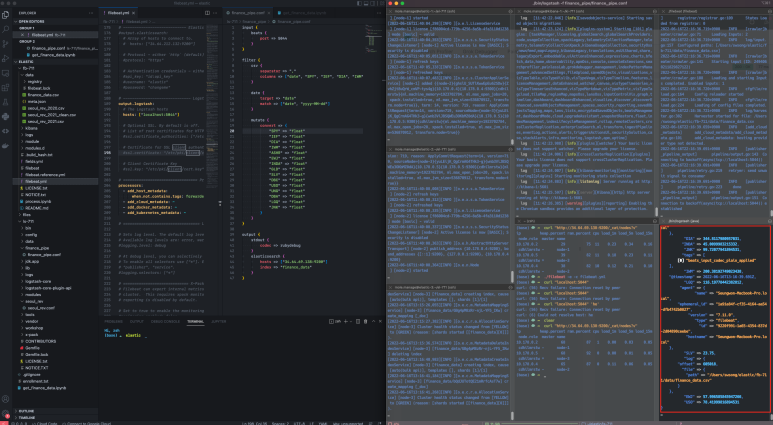
Step 6. 키바나 인덱스 패턴 설정
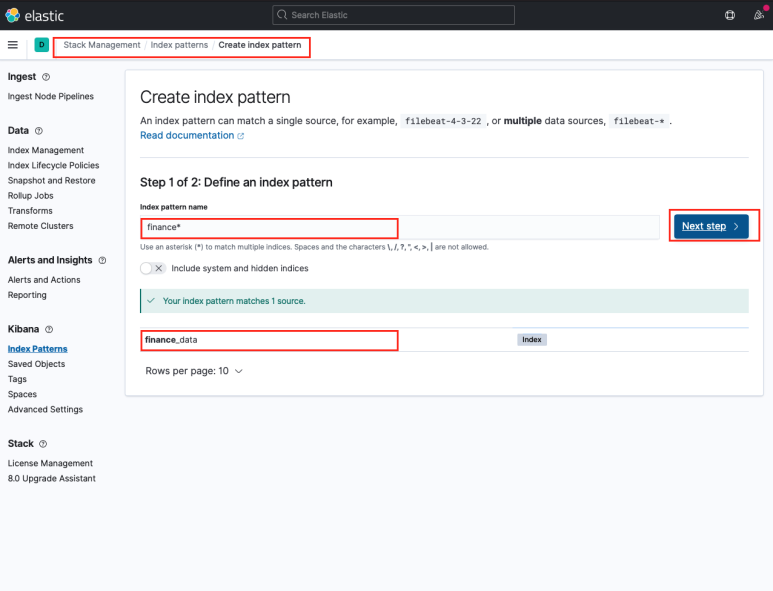
키바나에서 대시보드를 만들기 위해서는 인덱스 패턴을 설정해 줘야 한다. 이 패턴을 통해 대시보드가 각 칼럼과 데이터 타입을 인식한다. Stack Management 메뉴에 Index patterns 탭에 들어와서 진행할 수 있다.
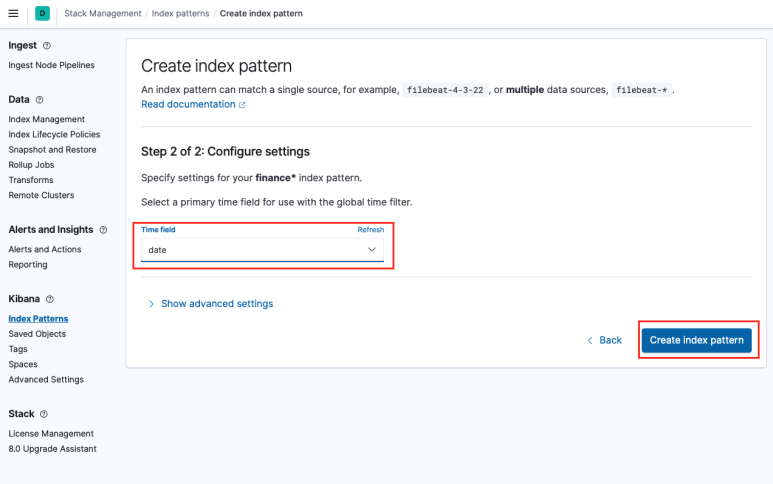
일반적으로 키바나 대시보드는 서버 로그를 모니터링하는 용도로 사용된다. 따라서 데이터 집계 기준이 되는 타임 테이블을 가장 먼저 정의해 준다.
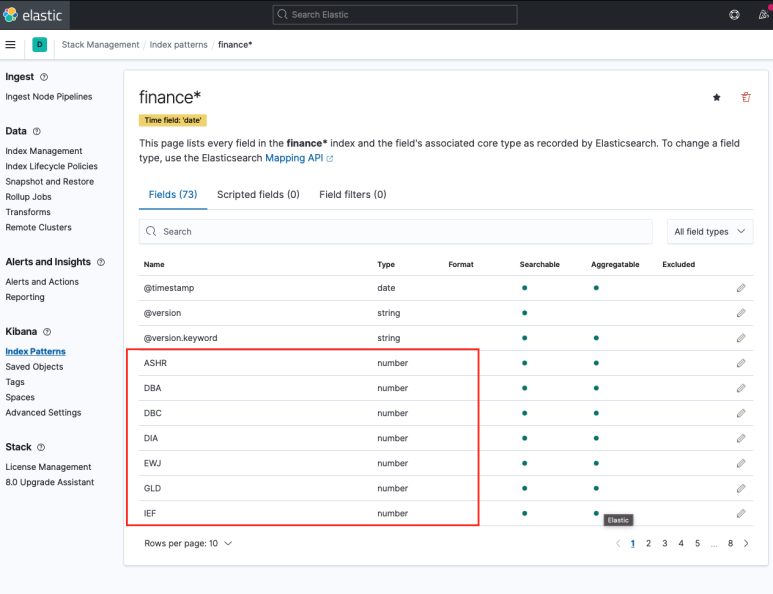
인덱스 패턴을 생성하면 아래와 같이 필드명과 데이터 타입을 확인할 수 있다. 숫자형 필드가 모두 number로 잘 들어왔는지 체크해 준다.
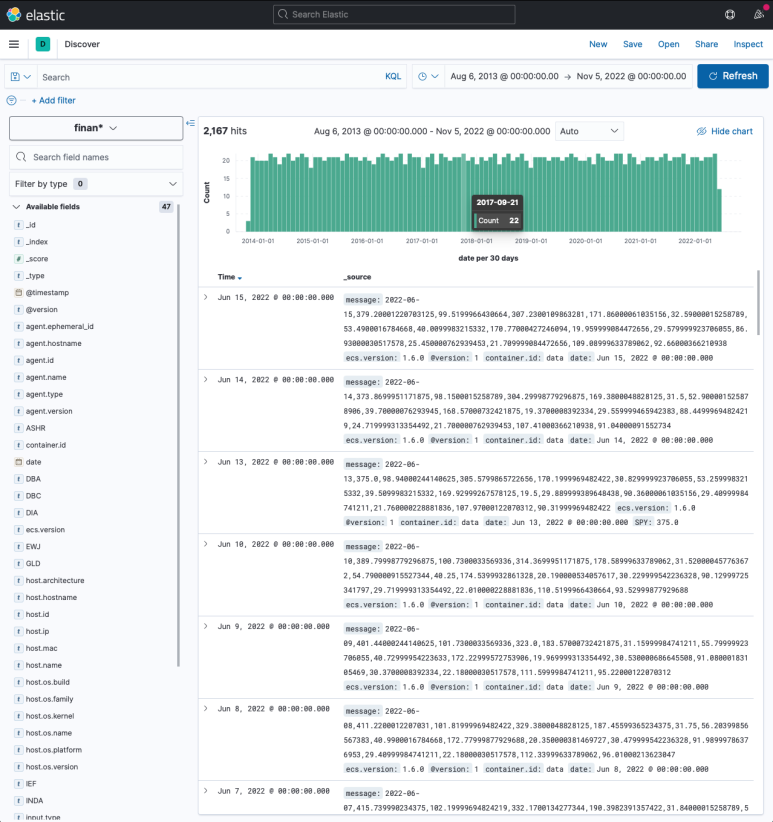
참고로, Discover 메뉴로 들어가면 해당 인덱스 패턴에 대한 자세한 필드 정보를 시계열로 확인할 수 있다.
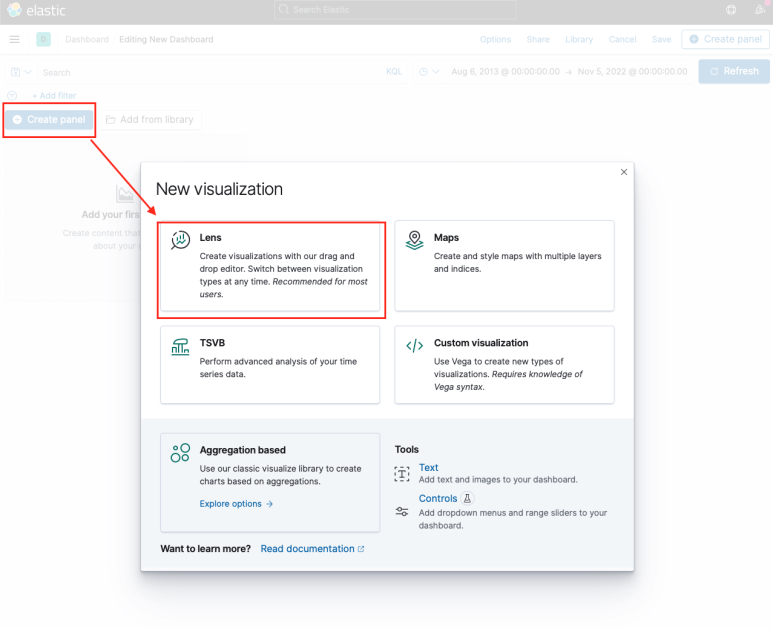
Step 7. 대시보드 구성
메뉴에 대시보드에 들어가면 패널을 생성할 수 있다. 대시보드는 패널 조합으로 구성되며, 패널은 하나의 View(그래프, 집계) 단위라고 보시면 되겠다.
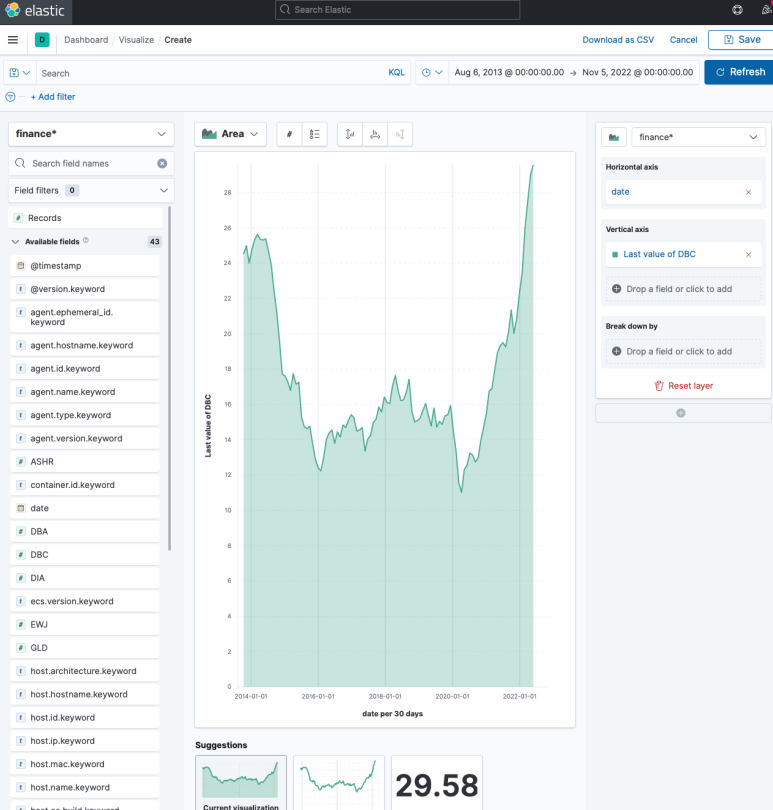
패널 생성 화면으로 들어가면 이렇게 인덱스 패턴(finance*)을 지정하고, 해당 패턴에 속하는 필드들로 차트를 구성할 수 있다. 차트를 자유롭게 구성한 다음 Save를 눌러준다.
이 과정을 반복하며 패널을 생성해 주면 대시보드가 아래와 같이 구성된다.
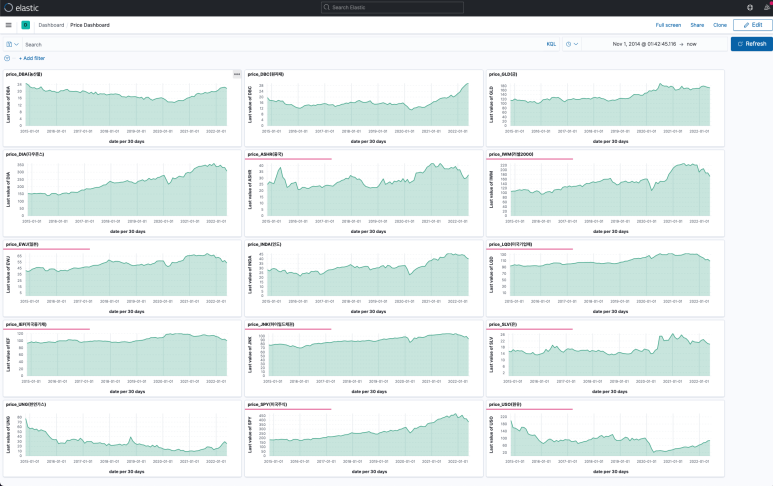
이렇게 다양한 글로벌 경제 매크로를 확인할 수 있는 대시보드를 간단히 구현해 보았다.
엘라스틱 스택은 실시간 모니터링과 검색에 최적화된 파이프라인 조합이다. 그러므로 여기서 더 발전시켜 데이터 파일의 주기적(batch) 업데이트 혹은 실시간 데이터 전송 프로세스 구축을 통해 매일 변화하는 지표와 데이터를 실시간으로 보여주는 모니터링 서비스를 만들어보시길 추천드린다.