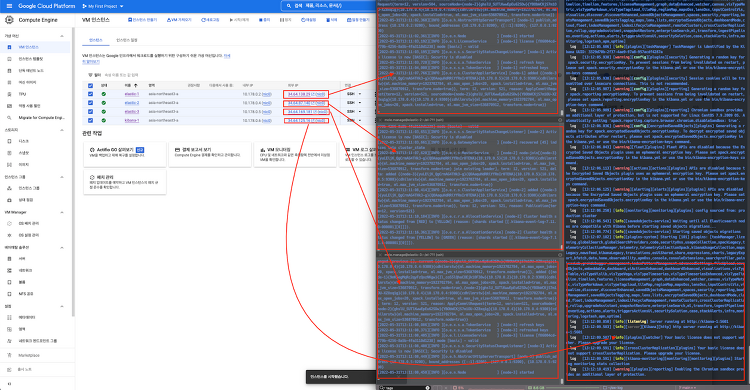
데이터 파이프라인 구축 (1)에서 csv 파일의 텍스트 전처리가 필요했다. 해당 부분부터 이어서 kibana 대시보드 작업까지 진행한다. 지난 글에서 작성했지만, 작업환경과 파이프라인 flow도 다시 보자. """ 작업 환경: Macbook Pro 2019 - i9, 16GB GCP 가상 머신 4대 할당(e2-small 3대 + e2-medium 1대) 가상 머신 1대에 클러스터 1개 배치(클러스터당 노드도 1개씩) filebeat 설치(Local) logstash 설치(Local) elastic search 설치(e2-small 3개 각각 설치) kibana 설치(e2-medium 1대에 설치) 데이터: 서울시 상권 추정 매출(서울시 열린 데이터 광장 제공) 구축할 데이터 파이프라인 Flow: Beat..