Step 0. 파이어스토어 서비스 계정 생성
파이어스토어는 구글에서 제공하는 클라우드 기반 NoSQL 데이터베이스다. 따라서 구글 클라우드 계정이 있어야 하며, 만약 처음이라면 GCP에 접속 후 IAM 관리자에서 서비스 계정을 생성해 준다.

계정을 생성하면 자동으로 인증키 파일(.json)이 다운로드 된다. 해당 파일을 가지고 아래와 같이 인증 후 데이터베이스 객체를 생성해 주자.
Step 1. 데이터 전송하기
먼저, 파이어스토어에 전송할 데이터를 확인한다.
이제 데이터를 전송할텐데, 파이어스토어에 데이터가 저장되는 방식은 다음과 같다.
- 데이터베이스 최상단(루트)에 collection을 생성할 수 있고,
- 각 collection에는 문서를 집어넣는다.
- 문서 안에는 필드-필드값 쌍으로 이루어진 데이터를 포함한다.
즉, "컬렉션 > 문서 > 데이터(필드-필드값)"의 형태로 데이터베이스를 구성하게 되며, 이 형식에 맞춰서 데이터를 전송하면 되겠다.
키-값 쌍으로 데이터를 보내줄 것이다. 아래와 같이 실행해 주면 각 컬럼을 순회하며 날짜별 종가 데이터가 들어간다.
참고로, db.collection(collection_name).document(document_name)에서 collection_name과 document_name이 DB에 없는 경우 자동으로 생성된다. 해당 코드의 경우 collection_name은 'price', document_name은 각 컬럼명이므로, 아래와 같이 파이어스토어 DB가 생성되면 정상적으로 데이터가 넘어간 것이다.
Step 2. 데이터 불러오기
파이어스토어에 저장된 데이터를 다시 불러오는 것도 간단한다. 어떤 collection을 가져올지 정의해 주고, stream() 함수를 통해 해당 collection 내 documents를 순차적으로 가져온다.
위 이미지의 하단 cell에서 볼 수 있듯이 stream()을 통해 반환되는 객체는 generator이다. 파이썬에서 모든 generator는 iterator이므로, 해당 제너레이터를 반복 호출하면서 호출되는 복수의 데이터 컨테이너로부터 데이터를 가져올 수 있다. 여기서, 반복 접근하는 복수의 컨테이너는 'document'가 되겠다.
각 document는 필드(키)와 필드값 쌍으로 구성되어 있기 때문에 컨테이너(document)를 파이썬 dictionary로 변환해 주면 id 값에 해당하는 데이터를 아래와 같이 불러올 수도 있다.
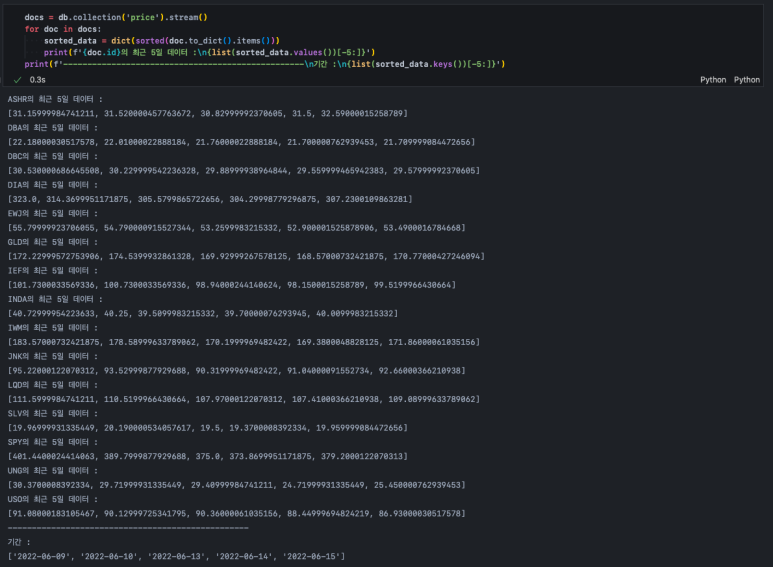
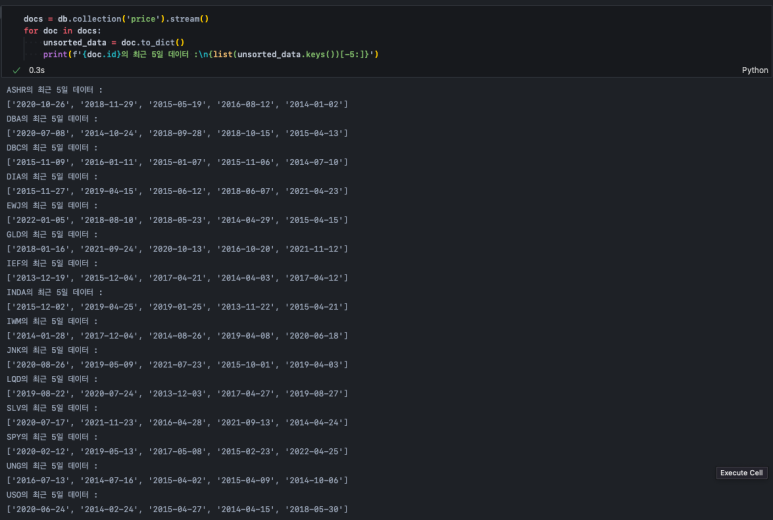
참고로 데이터를 불러올 때 키값에 따라 정렬을 해줬는데, stream()은 처음 저장된 순서로 데이터를 가져오지 않기 때문에 그렇다. 만약 정렬하지 않고 데이터를 불러오게 되면 아래와 같이 날짜가 섞이게 되고 각 document마다 그 순서는 다르다. 따라서 이를 그대로 병합해버리면 문제가 생긴다.
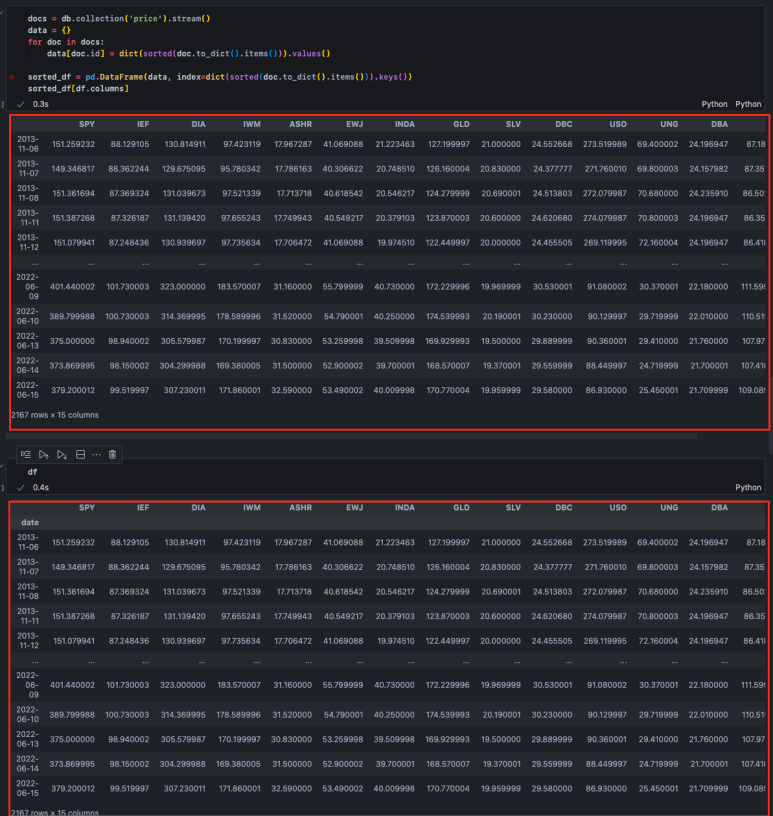
그러나 정렬한 데이터로 병합해 주면 아래와 같이 우리가 처음 파이어스토어에 보냈던 소스 데이터(df)와 동일한 DataFrame을 생성할 수 있다.
Step 3. 데이터 시각화
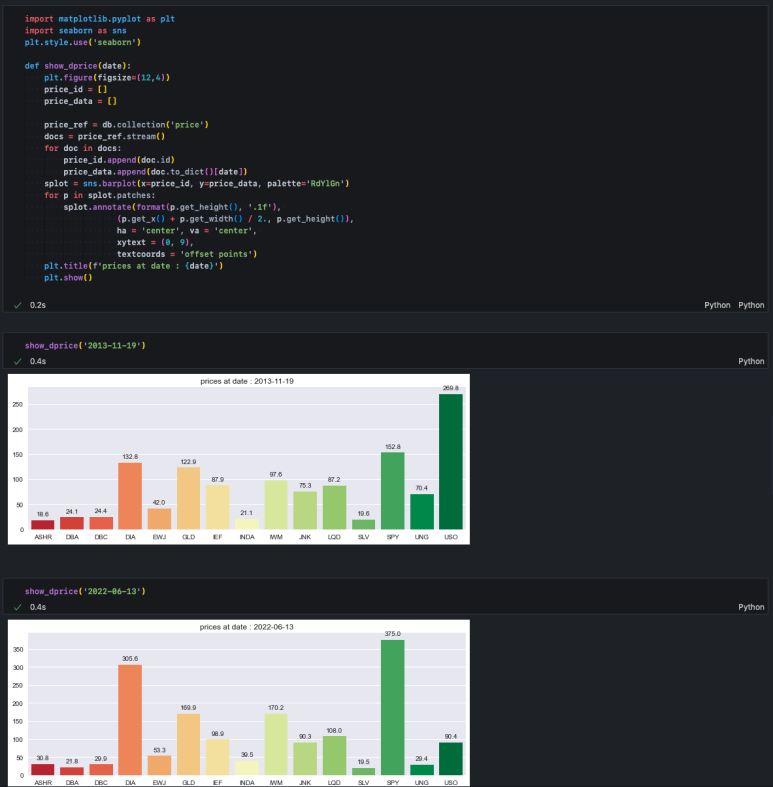
일회성 분석이라면 굳이 데이터 프레임을 생성하지 않고, 필요한 특정 날짜의 데이터만 메모리에 올린 다음 차트를 그릴 수도 있다.
이외에도 파이어 스토어는 다양한 함수를 제공한다. stream()을 사용하기 전에 order_by 함수로 미리 정렬한 다음 불러올 수도 있고, where 함수로 필요한 데이터만 쿼리 해서 불러올 수도 있다. 단, 이때는 용도가 다르기 때문에 분석 흐름에 맞게 필드-필드 값도 다르게 설정해 줘야 한다.
예를 들어 현재는 필드-필드값이 날짜와 해당 날짜의 가격 쌍(ex. ID : SPY, '2013-11-06':151.259232)으로 이루어져 있는데, 이를 date : [날짜 목록], price : [가격 목록] 과같이 바꿔주면 되겠다.