Step 1. 데이터 불러오기

이제 데이터 불러오는 것은 어렵지 않습니다. yfinance 라이브러리를 사용해 테슬라(TSLA) 주가 정보를 가져오겠습니다. stocks 인스턴스를 생성했고, 객체 내에 내장된 history() 함수로 2010년부터 최근 데이터까지 가져왔습니다. (작성 시점: 2022-07)
Step 2. 차트 시각화
파이썬에서 사용하는 대표적인 시각화 라이브러리는 matplotlib과 seaborn이 있습니다. 여기서는 matplotlib을 사용해 차트를 그리는 법을 배워보겠습니다. 참고로 seaborn은 matplotlib을 기반으로 더 다양한 색상과 통계 차트를 제공하고 있으니, 검색해 보시길 권장 드립니다.
처음 보는 라이브러리를 사용하게 되면 어떻게 구현되어 있는지 깃허브 등을 통해 살펴보면 좋습니다. 모든 라이브러리마다 들여다보는 것은 효용이 좋지 않겠지만, 관심을 가지고 여유로울 때 살펴보면 라이브러리를 유연하게 잘 사용하는 데에 많은 도움이 될 것입니다. matplotlib은 한 번 내부를 먼저 살펴보도록 하겠습니다.
github 주소로 들어가면 lib 폴더가 보입니다. 바로 여기에 matplotlib으로 사용할 수 있는 패키지들이 내장되어 있습니다.
여기서 matplotlib 폴더를 한번 더 들어가주면 아래와 같이 pyplot.py 모듈을 확인할 수 있습니다.
내부에 들어가 보면 우리가 pyplot을 통해 자주 사용하는 figure()나 subplot() 등의 유용한 함수들이 얼마나 정교하게 잘 개발되어 있는지 살펴볼 수 있습니다.
이런 식으로 파이썬 라이브러리를 사용할 때, 라이브러리가 어떻게 구현되어 있는지 관심을 가지고 살펴보면 코드와 조금 더 친해질 수 있습니다.
2-1. 기본 선 그래프
다시 돌아와서, matplotlib의 pyplot 모듈을 plt라는 이름으로 불러오겠습니다.
plt.style.use() 함수를 사용하면 그래프 스타일을 적용할 수 있습니다. 여기서는 seaborn 스타일을 적용했으나 다른 스타일도 확인해 보고 싶다면 링크를 참고해 주세요.
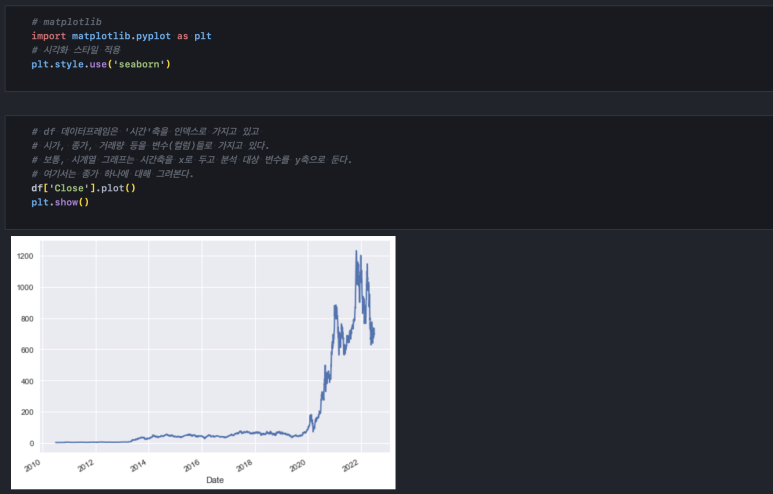
우리는 df 변수에 데이터 프레임을 담았습니다. 'Close'컬럼만 불러와서 데이터 프레임에 내장된 plot() 함수를 사용해 주면 이렇게 차트가 그려집니다. 이때, x축은 df의 인덱스, y 축은 'Close' 변수가 됩니다.
plt.show()는 print() 함수와 비슷한 역할을 한다고 생각해 주세요. "차트를 그려라" 하고 명령하는 것입니다.
데이터 프레임 내장 함수가 아닌 pyplot의 plot() 함수를 사용할 수도 있습니다. 결과는 같습니다.
2-2. 그래프 채우기
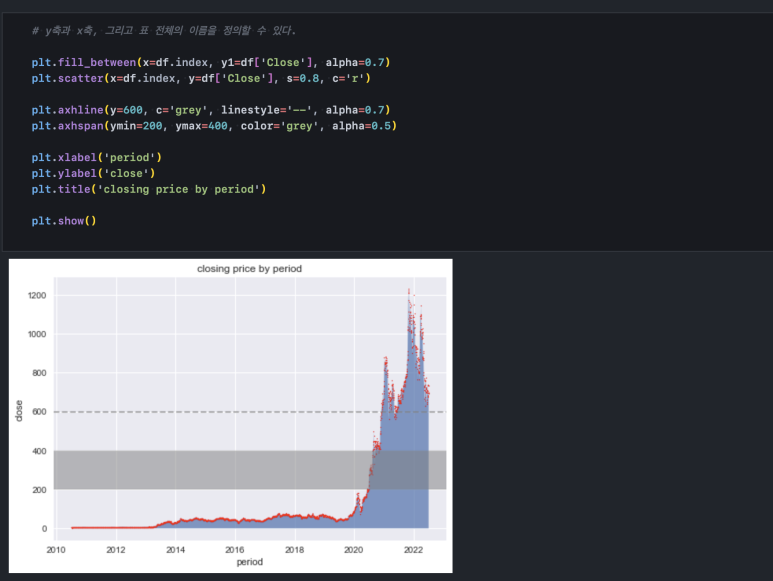
pyplot()의 fill_between() 함수를 사용하면 plot() 함수를 사용했을 때 생기는 선형 그래프 아래 영역을 채워줄 수 있습니다.
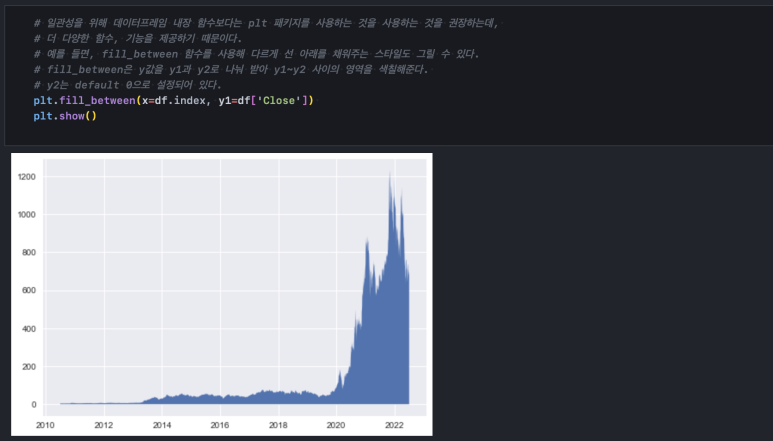
alpha 파라미터로 색상 농도를 조절할 수 있습니다. 1이 default이며, 0으로 갈수록 희미해집니다.
2-3. 산점도
pyplot은 단순 선형 그래프 외에도 다양한 그래프를 지원합니다. 데이터가 흩어진 정도를 보여주는 산점도는 시계열 데이터 상에서 얼마나 밀집해있는가를 확인하기 위해서도 쓰입니다. 산점도를 그리려면 scatter() 함수를 사용하면 됩니다.
s 파라미터를 넣지 않으면 점의 크기가 매우 커서 보기 좋지 않을 것입니다. 위와 같이 s=0.8 정도로 지정해 주면 충분한 양의 데이터를 대부분 보기 좋게 그려줍니다.
fill_between() 함수와 scatter() 함수의 실행 결과를 한 번에 보여줄 수도 있습니다. plt.show()가 '그려라'라는 역할을 하기 때문에 순서대로 작성해 주고 마지막에 plt.show() 함수만 실행해 주면 됩니다.
2-4. 기준선 및 구간 표시
우리가 프레젠테이션을 하거나 어떤 설명을 할 때, 차트를 놓고 x축 혹은 y 축에 기준선을 표기해 줄 때가 많습니다. 이럴 때에는 axvline(), axhline() 함수를 사용할 수 있습니다. 만약 기준선이 아니라 기준 영역을 그리고 싶다면 axvspan(), axhspan() 함수를 사용하면 됩니다. 색상과 스타일 등은 아래와 같이 파라미터로 적용할 수 있습니다.
2-5. 타이틀 표기
y 축과 x축에 단위 표기나 이름(label)을 설정해 줘야 할 수도 있습니다. 그리고 그래프의 제목을 표기하고 싶을 때도 있습니다. ylabel(), xlabel() 함수는 각 축에 해당하는 위치에 텍스트를 작성하게 해주고, title()은 그래프 위에 타이틀을 작성하게 해줍니다.
Step 3. 장/단기 추세
3-1. 3일 이동 평균
주가 추세를 분석하거나 기술적 지표를 확인할 때 이평선(이동평균선)이라는 용어가 자주 쓰입니다. 지난 n 일 간의 가격 평균을 연속해서 보여주는 것인데, n 일이라는 기간 동안 만들어진 추세를 시간의 흐름에 따라 살펴볼 수 있는 유용한 지표입니다.
이동평균 데이터는 파이썬으로도 간단하게 확인할 수 있습니다. Close(종가)에 대해 rolling(n) 함수를 적용하면 n 일에 대한 통계치를 계산할 수 있는 객체가 됩니다. 이 객체는 n 일간의 데이터를 담고 있으며 min(), std(), median(), mean() 함수를 통해 n 일간의 통계치를 계산할 수 있습니다. 여기서는 mean() 함수를 사용해 간단히 3일 이동평균 데이터를 구해보았습니다.
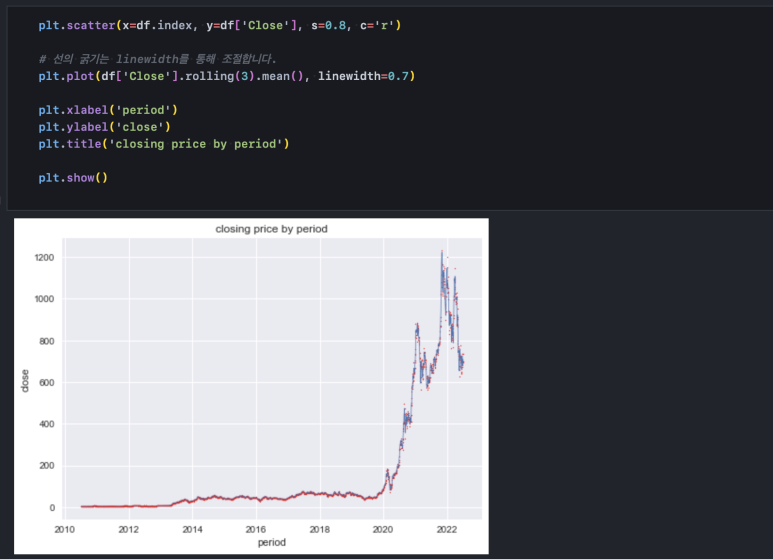
fill_between()과 scatter() 함수로 차트를 겹쳐 그릴 수 있었던 것처럼 이동평균선도 산점도와 함께 그릴 수 있습니다.
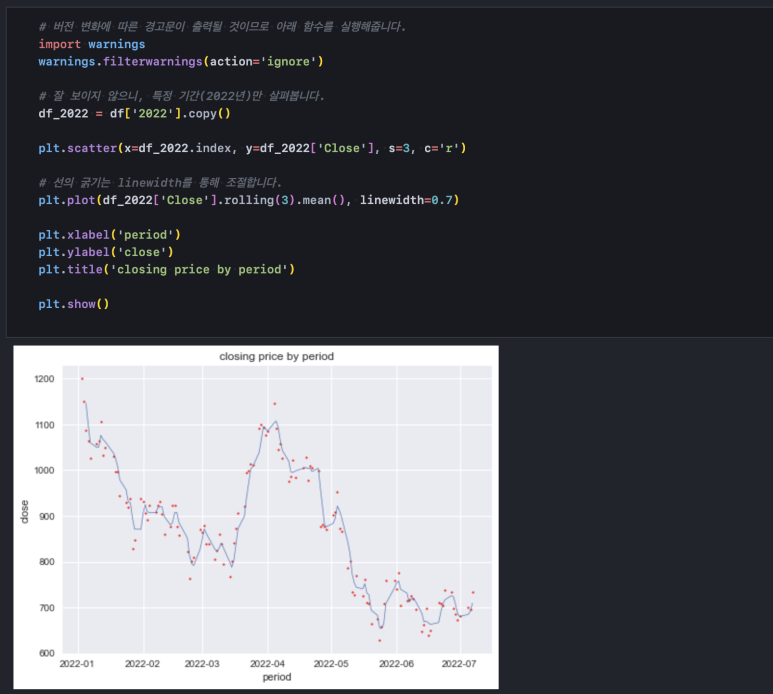
데이터 범위(기간)가 너무 커서 잘 보이지 않네요. 2022년만 확대해서 살펴보겠습니다. 이때는 인덱싱을 통해 2022년만 추출하면 됩니다. 시계열 데이터를 인덱싱할 때에는 간단히 '2022' 숫자만 넣어주면 2022년에 해당하는 데이터를 모두 가져옵니다. 단, 겉보기에 시계열 데이터라도 데이터 타입이 문자열이거나 실수형일 수 있으니 문제가 생긴다면 인덱스가 datetime64 타입이 맞는지 확인해야 합니다.
3-2. 30일 이동 평균
이번에는 30일 이동 평균 그래프를 그려볼 것입니다. rolling(n) 함수에 n만 바꿔주면 됩니다. 30일 치 이동평균이기 때문에 첫 29일까지는 평균값이 없습니다. axvspan() 함수를 통해 평균값이 있는 기간을 같이 표시해 보겠습니다.
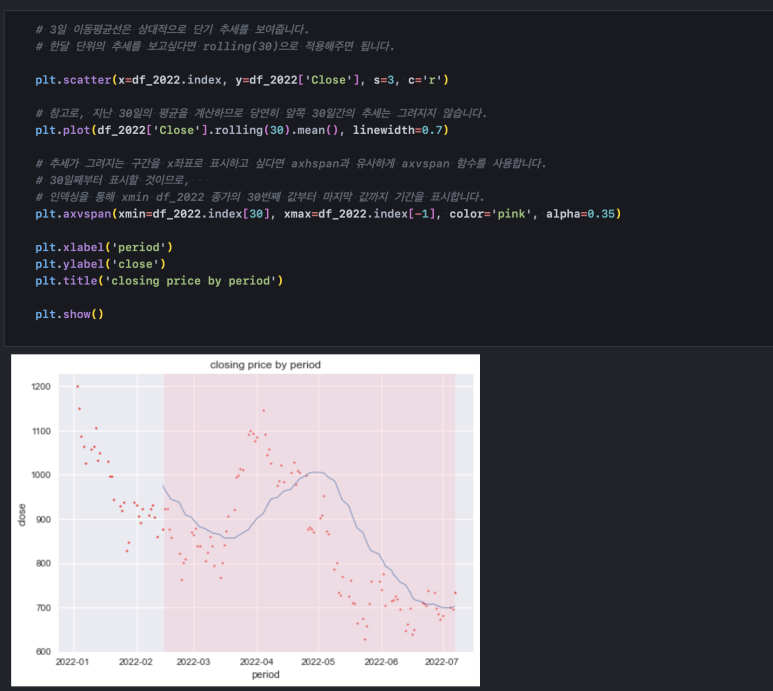
Step 4. 시계열 분해
4-1. 장기 주가 데이터
시계열 데이터에는 이렇게 이동평균으로 확인할 수 있는 추세만 있는 것이 아니라 계절성과 잔차라는 요소가 있습니다. 계절성은 관측치(observed, 주가)에서 추세(trend)를 제거하고 남은 데이터 중 반복되는 패턴을 잡아서 보여주며 잔차(residual, resid)는 계절성까지 제거되고 남은 값을 보여줍니다. 따라서 잔차에서는 특정 반복 패턴, 커지거나 작아지는 움직임, 급격히 튀는 구간 등이 남아 있으면 안 됩니다. 모든 패턴과 움직임이 추출되고 남은 '나머지'는 random, 즉 무작위적 변동성이어야 하기 때문입니다.
seasonal_decompose 함수는 이러한 값들을 한 번에 뽑아낼 수 있도록 해줍니다. statsmodels 라이브러리에서 가져와 사용할 수 있습니다.
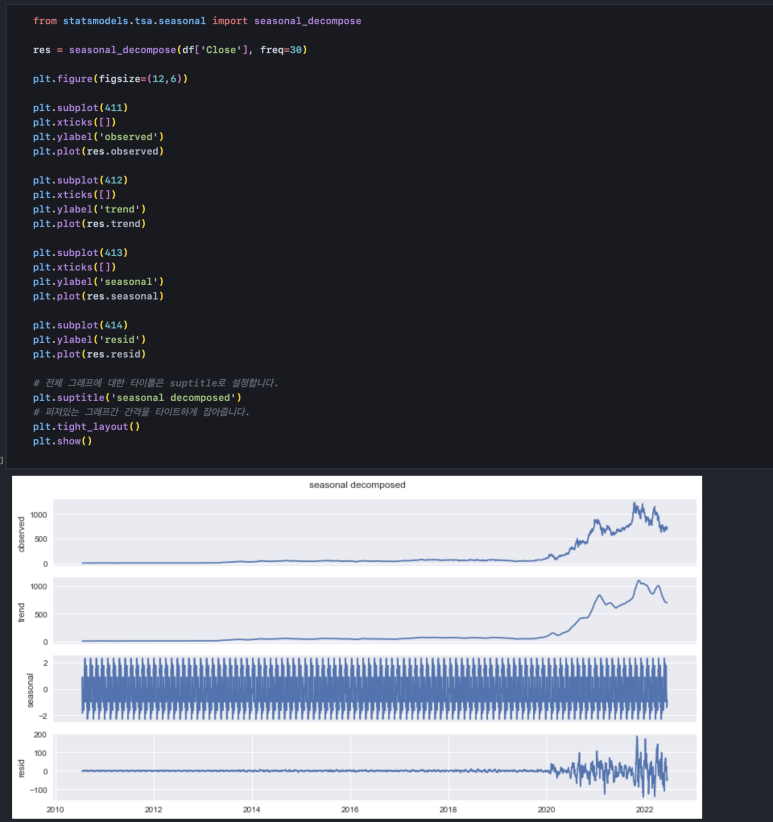
seasonal_decompose 함수에는 관측할 시계열 데이터와 추세를 추출할 기간을 입력해 줍니다. 30일 치 이동평균을 추세 추출 기준으로 잡았기 때문에 freq=30으로 설정해 주었습니다. 이렇게 생성된 인스턴스는 res라는 변수에 담고, res.observed, res.trend, res.seasonal, res.resid를 통해 각각 관측치, 추세, 계절성, 잔차를 뽑아낼 수 있습니다.
다음으로 시각화 부분입니다. pyplot은 figure() 함수를 제공합니다. 여기에 figsize=(x, y)를 지정해 주면 x축 크기, y 축 크기를 설정할 수 있고, subplot() 함수로 설정된 크기를 나눠서 할당해 그래프를 그릴 수 있습니다.
subplot(xyi)와 같이 사용하는데, 이는 x 행 y 열만큼의 서브 그래프 공간을 할당하여 i 번째 위치에 그래프를 그리겠다는 의미입니다. 예를 들어 subplot(411)의 경우, 4행 1 열짜리 서브 그래프 공간을 할당하여 맨 위쪽에 그래프를 그립니다. 여기서는 observed 그래프가 되겠습니다.
plt.xticks()는 x축을 의미하는데, 빈 리스트([])를 넣어주면 x축을 표시하지 않게 됩니다. subplot()을 총 4개 사용했고, 맨 하단 그래프가 x축을 표시해 주고 있기 때문에 나머지 위쪽 3개는 x축을 표시하지 않도록 plt.xticks([])를 작성해 주었습니다.
다음으로, plt.suptitle()은 이렇게 서브 그래프를 그릴 때 통합 타이틀을 기재해 줄 수 있습니다. 여기서 plt.title()을 쓴다면 해당 위치의 서브 그래프에만 타이틀이 기재될 것입니다.
여기서 주의 깊게 봐야 하는 부분은 '잔차(resid)'인데, 잔차가 2020년 이전과 2022년 이전, 이후 움직임이 크게 다릅니다. 이렇게 잔차의 움직임 변화가 눈에 잘 보이면 제대로 패턴을 추출해 내지 못한 것입니다. 잔차는 앞에서 언급한 것처럼 '무작위성'을 보여야 하기 때문입니다. 진폭이 점점 커지는 것도 '발견 가능한 패턴'의 일종입니다.
4-2. 단기 주가 데이터
이때, 우리는 잔차가 일정한 범위 내에서 불규칙성을 보이는 2022년만 보면 어떨까?라고 생각해 볼 수 있습니다.
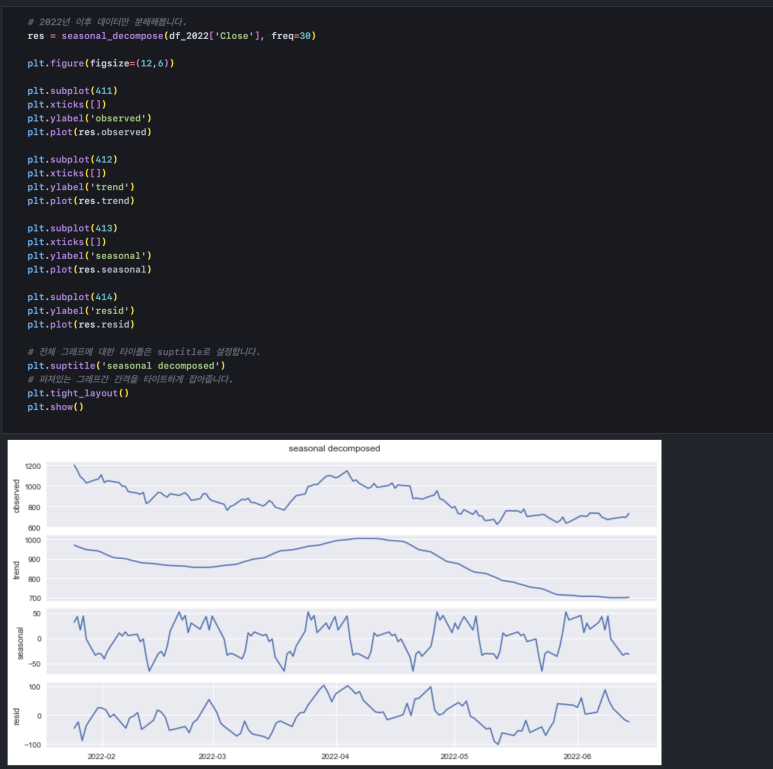
그러나 이렇게 했을 때 데이터가 너무 적어져서 잔차가 정말 랜덤 한지 판단하기 어렵습니다. 따라서 분 단위 데이터를 확보하거나 충분한 기간의 데이터에 적절한 처리를 해줘서 잔차의 랜덤(무작위)을 확보해야 합니다.
4-3. 장기 로그-주가 데이터
그래서 일반적으로 주가 분석을 할 때에는 로그를 취해줍니다. 로그를 취하면 y 값(Close)의 움직임 폭을 좁혀주는데, 이는 급격한 추세로 인해 가파르게 상승하거나 하락하는 구간을 희석시키는 역할을 합니다.

로그-주가 데이터를 구하기 위해 행렬 및 수치 연산에 활용되는 numpy 라이브러리를 np라는 이름으로 불러와 log() 함수를 사용해 주었습니다. observed를 보면 기존 주가 데이터와 움직임은 유사하나 최근의 급격한 가격 상승으로 보이지 않던 과거의 움직임도 잘 표현되고 있는 것을 확인할 수 있습니다.
잔차도 전체 기간에 걸쳐 일정한 범위 내에서 무작위로 진동하는 것을 볼 수 있기 때문에 로그를 취한 주가 데이터에서 드러난 추세는 유의미합니다.(정확히는 유의미성을 확인할 근거를 확보했다고 보는 것이 타당합니다. 추세에 대한 정규성 검정과 관측치의 자기상관성 여부를 확인한 다음에야 시계열의 정상성을 확보할 수 있고 그때 추세분석이 유의미한가를 판단할 수 있기 때문입니다. 다만 여기서는 프로그래밍을 배우는 것이기 때문에 더 디테일한 분석까지 진행하지는 않겠습니다.)
4-4. 장기 로그차분-주가 데이터
로그를 취했음에도 잔차에 패턴이 남아있거나 유의미한 추세를 판단하기 어려운 경우 차분(미분)을 한 번 더 수행합니다. 차분은 '변화'를 의미합니다. 즉, 일별 주가 데이터에 미분을 하면 일일 가격 변화량이 됩니다. 여기서는 그전에 로그 처리가 되어 있기 때문에 로그를 취한 주가 데이터의 일일 변화량이 되겠네요.
차분의 효과는 일간 변화량을 보여주는 것 이상으로 중요한 의미가 있습니다. 바로 과거의 움직임을 현재의 움직임과 같은 비중으로 확인할 수 있다는 것입니다. 현재 주가가 과거 주가보다 훨씬 많이 올라와 있는 상태라면 과거의 1%보다 현재의 1%가 더 큰 영향을 미칩니다. 앞서 로그를 취한 것도 어느 정도 이러한 영향을 상쇄하기 위해서지만 로그를 취한 관측치(observed)를 보면 여전히 상승 추세가 있기 때문에 현재의 1%는 과거의 1%보다 더 사이즈가 큽니다. 따라서 여기에 대해 미분을 통한 '변화량'을 y 축에 두게 되면 과거와 현재의 움직임을 '변화'라는 동일한 기준으로 파악할 수 있게 됩니다. 즉, 과거나 현재나 1%는 동일하게 1%입니다.
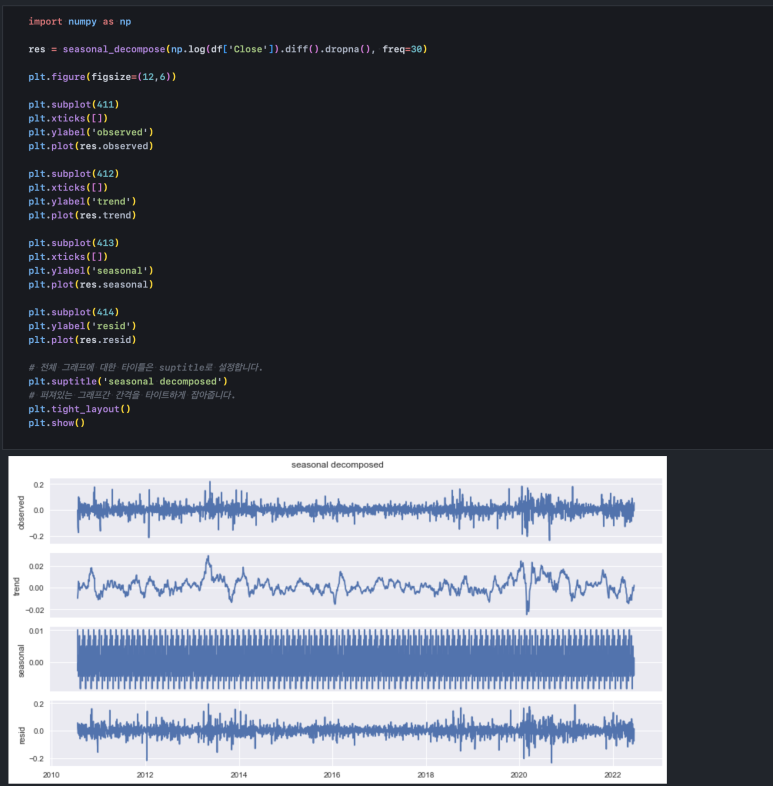
하지만, 로그를 취했을 때 충분히 random 한 잔차를 확보할 수 있었고 우리가 파악하길 원했던 추세 정보를 얻었다면 로그 차분을 해줄 필요는 없습니다. 목적과 다르게 추세조차 파악하기 어려워졌기 때문입니다.
여기서 우연히 우리는 '일일 변화량'(차분 값)이 '무작위성'을 보인다는 것을 발견했습니다. 로그만 취했던 데이터를 보면 장기 추세는 우상향하는 방향으로 나아갔습니다. 그러나 로그 차분 데이터는 랜덤에 가깝습니다. 이는 가격의 움직임은 추세가 있지만 가격 변화의 움직임은 추세가 없다는 것을 의미하고, 추세는 장기적으로만 유의미하다고 해석할 수 있습니다.
투자의 관점에서 보면 우리가 주가라는 정보만 놓고 투자 의사결정을 할 때, 장기적인 추세에 따라 주가가 오를 것이라고 판단할 수는 있겠지만 내일 주가가 오늘보다 오를 것이냐 떨어질 것이냐는 알 수 없다는 것입니다.
이는 자기상관분석을 통해서 검증할 수 있습니다.
Step 5. 자기상관분석
자기상관분석은 단일 데이터(주가)가 스스로에게(과거로부터) 영향을 받아 움직이는가?를 판단하기 위한 분석 기법입니다.
일반적으로 시계열 분석을 할 때, 위에서 잠깐 언급한 '정상성'을 확보한 다음 회귀분석 등의 예측을 수행할 수 있는데 '정상성'의 근거가 되는 요소 중 하나가 '자기상관성이 없다'입니다. 그래서 주가만 놓고 회귀분석을 실시하면 마치 미래를 예측하는 것 같지만 이는 사실 정상성을 확보하지 못한 분석으로 유의미한 결과가 아닙니다. 그래서 위와 같이 로그 차분 등의 전처리를 수행하여 정상성을 확보한 다음 분석으로 넘어가는 것이 바람직합니다.
5-1. 기본 종가 데이터
파이썬으로 자기상관성을 확인할 때는 시계열 분해 때 봤던 statsmodels를 사용하면 됩니다.
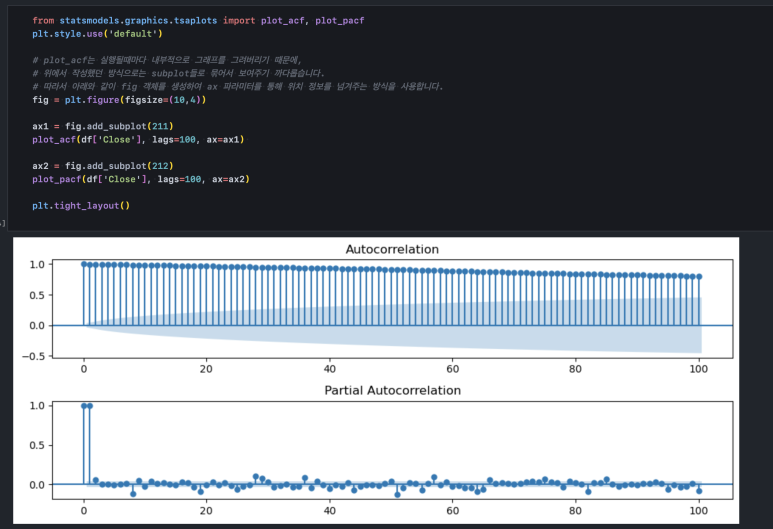
함수는 2개를 사용했습니다. 하나는 plot_acf(), 다른 하나는 plot_pacf()입니다.
plot_acf()는 auto-correlation을 계산합니다. auto-correlation은 단순 자기상관성으로, 오늘과 어제, 어제와 그제와 같이 1개 단위(1일 간격)의 상관성을 보여줍니다.
plot_pacf()는 partial auto-correlation을 계산합니다. partial auto-correlation은 편 자기상관성으로, 오늘과 어제, 오늘과 그제와 같이 오늘을 기준으로 1~n 개 단위(하루~n 일)의 상관성을 보여줍니다. 함수를 사용할 때 lags 파라미터를 지정해 주었는데, 오늘로부터 과거 100일까지의 상관관계를 보여달라고 한 것입니다.
둘 다 1에 가까울수록 상관성이 높고 0에 가까울수록 상관성이 낮다는 의미입니다. 0보다 아래에 있고, -1에 가까워지면 음의 상관관계, 즉 완전히 반대로 움직이는 성향이 있다는 것을 의미합니다. 보통 자기상관성에서는 그런 경향 자체가 모순이기 때문에 잘 나타나지 않습니다.
auto-correlation 그래프를 보면 지난 100일까지의 상관관계가 하루 단위로 매우 높게 나타나는 반면, partial auto-correlation 그래프에서는 가장 앞의 2개(오늘과 오늘, 오늘과 어제) 상관성만 높게 나타납니다. 이는 주가가 하루하루간의 연관성은 매우 크지만 이틀 이상 차이가 나면 연관성이 사라진다는 것을 뜻합니다.
다시 말하면, 오늘의 가격은 어제 가격으로부터는 영향을 받지만 그 전날 가격과는 무관합니다.
5-2. 로그 데이터
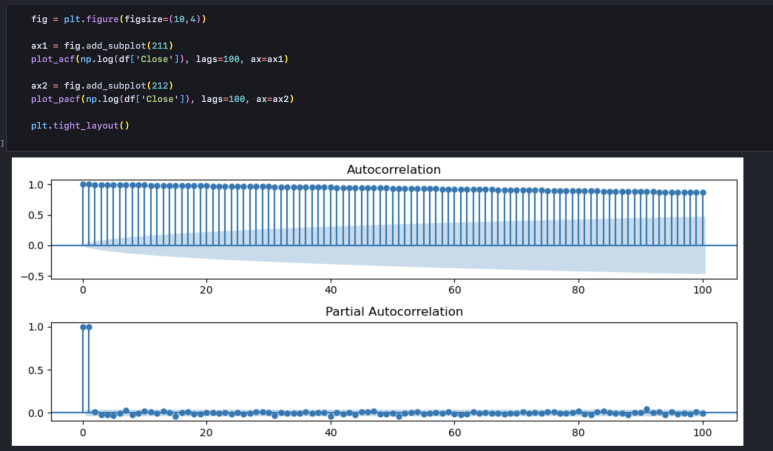
로그를 취한 종가 데이터의 자기상관성은 더 두드러집니다. 앞에 설명한 것처럼 급격한 변화가 로그 함수로 인해 상쇄되므로 추세가 더 선명하게 나타나는 것입니다.
5-3. 로그 차분 데이터
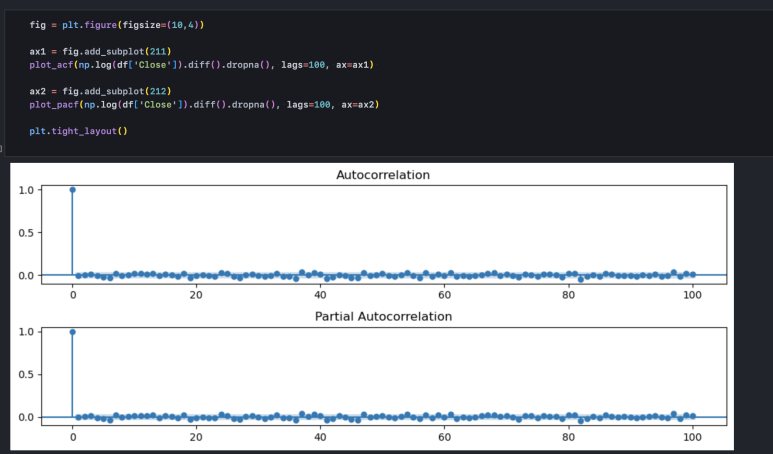
그러나 차분을 해주면 그 즉시 자기상관성이 완전히 사라집니다. 어제의 가격 변화로 내일의 가격 변화를 맞출 수 없습니다. 서로 관련이 없기 때문입니다.
이렇게 이번에는 데이터 시각화를 배워보면서 간단하게 시계열 분해와 자기상관분석까지 진행해 보았습니다. 데이터 분석을 배우기 어려운 가장 큰 이유는 분석 대상이 없기 때문입니다. 호기심을 가지고 분석 대상을 찾고, 어떤 분석을 할지 스스로 생각한 다음, 어떻게든 방법을 찾아가며 분석을 해보는 것이 좋습니다. 그것이 가장 빠르게, 그리고 효율적으로 파이썬이라는 도구를 배우는 방법입니다.