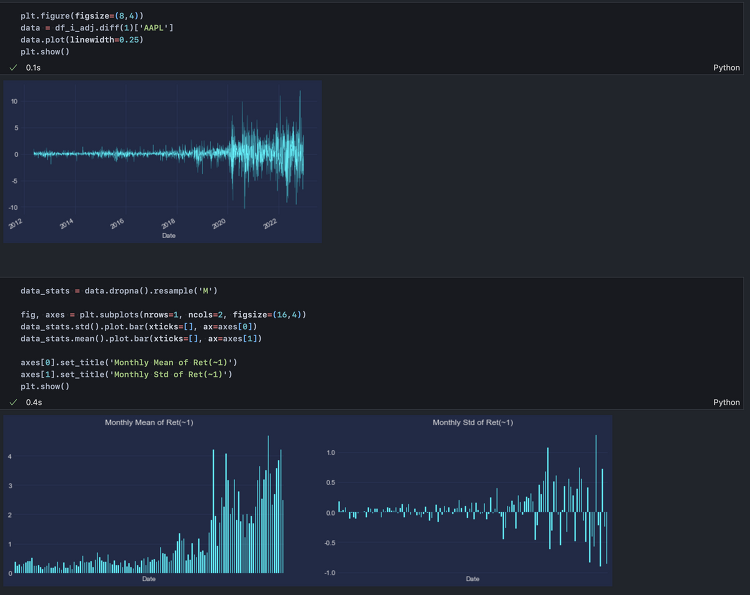
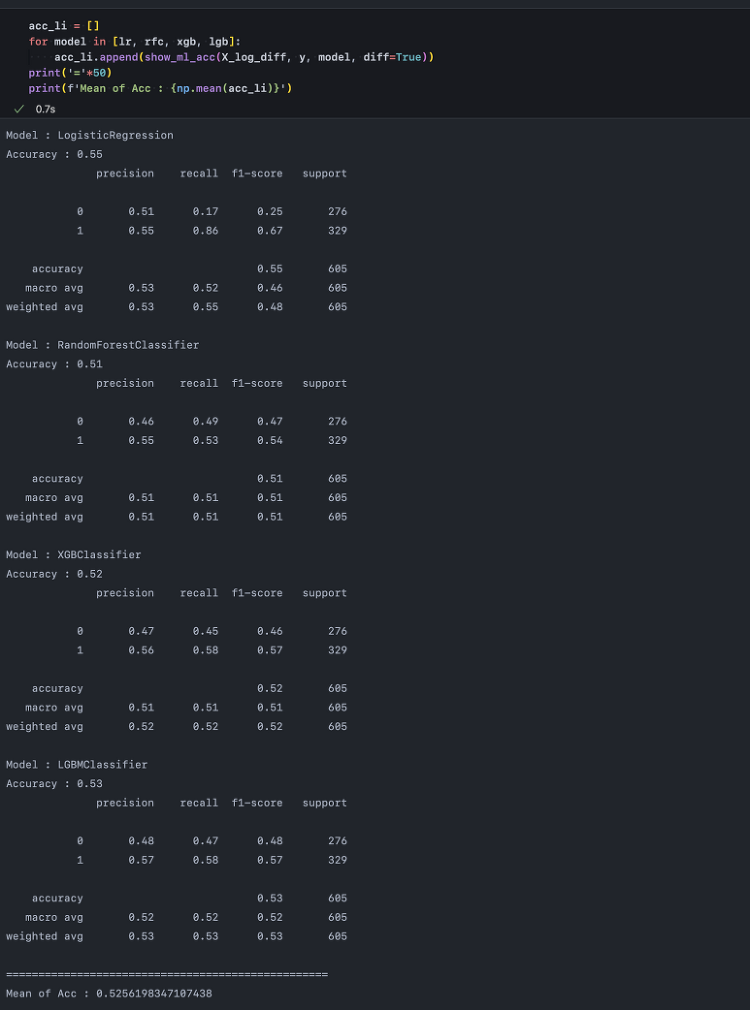
본 시리즈는 파이썬으로 시계열 자기상관 특성 및 마켓, 안전자산, 대체자산 등과의 동시간대 연관성을 분석하고 Apple Inc(AAPL) 주가를 예측한다. 튜토리얼 작성을 위해 금융전략을 위한 머신러닝(한빛미디어), 실전 시계열 분석(한빛미디어) 외 야후파이낸스 및 FRED API 공식문서 등을 참고하였으며 작업 과정에서 추가로 참고하게 되는 자료들은 이후 각 편 내에 서술하도록 하겠다. 1편에서는 간단히 데이터를 불러와 누락된 분포를 살피고, 시계열 기간을 동일하게 맞춘다. 그 다음, 예측에 필요한 데이터를 추출하기 위한 시계열 분석 작업을 간단히 수행하도록 한다. Step 1. Import Packages numpy와 pandas를 포함해 seaborn, matplotlib은 데이터 분석을 위해 언제..