본 장에서는 기계학습 방법론에 대해 간단히 알아본 다음, 파이썬 패키지로 제공되는 주요 기계학습 알고리즘을 사용해 보도록 하겠습니다.
Step 1. 데이터 불러오기
이번에도 역시 테슬라 주가를 불러오는 것부터 시작합니다.

Step 2. 예측값 정의
2-1. 기계학습
기계학습은 함수를 만드는 방식 중 하나입니다. y=ax+b라는 함수가 있습니다. 만약, 출력값이 입력값 대비 항상 2배가 되어야 하는 함수를 구해야 한다면 단순하게 a=2, b=0으로 설정하면 됩니다. 하지만 출력값이 입력값 대비 언제는 2배가 될 수도 있지만, 경우에 따라 1.5배가 되거나 어쩌면 -2배도 될 수도 있다면 함수를 어떻게 정의해야 할까요?
이때는 확률적 방법론을 사용해야 합니다. 경우에 따라 확률적으로 1.5배가 되거나 -2배가 될 수 있도록 하는 것입니다. 그런데 이것을 사람이 계산하는 것은 너무나 어려운 일이기 때문에 컴퓨팅 파워를 활용해 최적의 a와 b, 더 나아가 c ~ z까지 찾아내게 됩니다. 확률적 방법론은 오차의 발생 가능성을 내포합니다. 이러한 오차를 최대한으로 줄여나가는 과정을 '학습'이라고 하고, 더 줄일 수 없는 지점에 대해 '적합'되었다고 합니다. 충분히 줄이지 못한 지점에 대해서는 '과소 적합'되었다고 하고, 지나치게 줄인 지점에 대해서는 '과대 적합'되었다고 합니다. 적절한 적합 지점을 찾는 행위가 최적화 과정입니다.
이러한 기계학습의 유형은 크게 2가지입니다. 하나는 지도학습이고 다른 하나는 비지도 학습입니다. 사실, 앞에서 설명한 기계학습 방식이 지도학습입니다. 지도학습은 학습을 수행할 때 X(X_1, x_2, ...,x_n)와 y(정답, label)을 알려주고 둘 사이의 논리 구조를 찾아나갑니다. 반복적으로 예측을 수행하면서 예측값과 실제 값을 비교하고, 그 차이인 오차를 유의한 수준으로 줄이는 것이 학습의 목적입니다.
반면, 비지도 학습은 y가 주어지지 않습니다. X만 가지고 적절한 수의 그룹(군집)으로 나누는 테스크를 수행합니다. 극단적인 예로, 철수는 국어가 7점, 영어가 15점, 수학이 70점, 과학이 80점이고 영수는 국어가 100점, 영어가 99점, 수학이 3점, 과학이 2점이라고 하겠습니다. 또한 철수와 같이 국어와 영어보다 수학, 과학을 잘하는 학생들이 절반 있고, 영수와 같이 국어와 영어를 수학, 과학보다 잘하는 학생들이 절반 있다고 하겠습니다. 그러면 이때, 비지도 학습은 철수처럼 수학, 과학을 잘 하는 학생들을 A로 분류하고 영수처럼 국어, 영어를 잘 하는 학생들을 B로 분류할 것입니다. 우리는 A와 B로 나눠진 결과를 보고 "아, 문/이과로 나눴구나" 하고 판단할 수 있습니다. y(label)을 주지 않았기 때문에 모델은 이것이 문과인지 이과인지, 뭘 분류하는 것인지는 알 수 없지만 데이터상 2개 유형으로 나누는 것이 적합하다고 판단하는 것입니다. 이것이 비지도 학습의 대표적인 유형인 군집 분석입니다.
2-2. 지도학습
그중에서도 지도학습은 일반적으로 2개 유형의 테스크를 다룹니다. 하나는 예측이고, 다른 하나는 분류입니다. 지난 1주일 간의 주가 움직임을 보고 다음날 시가를 '예측'하거나, 다음날 시가가 어제 종가 대비 오를지, 내릴지를 '분류'합니다. 뉘앙스에서 알 수 있듯 사실상 분류도 예측의 일종으로 보기도 합니다. 예측의 대상이 이산적(ex. 0,1)이냐 연속적(ex. 0~1)이냐에 따라 분류 혹은 예측이라 정의하는 것이 보편적입니다.
좀 더 직관적으로 예를 들면, 대표적인 예측 기법인 회귀분석에 이진 분류 함수인 Sigmoid를 적용하면 로지스틱 회귀라는 분류 분석 알고리즘으로 바뀝니다. 이때, Sigmoid 함수는 모든 입력값에 대해 0과 1사이로 들어오도록 확률 값 변환 처리를 수행해 주는데, 그 확률 값을 기반으로 target이 0이냐 1이냐로 분류해 내는 방식입니다.
물론 모든 알고리즘이 이런 구조로 분류를 수행하는 것은 아닙니다. 본문에서 살펴볼 RandomForest, XGBoost, LightGBM 같은 Tree 기반 모델들은 애초에 분류를 수행하기 위한 목적으로 설계되어 있습니다. Tree 모델은 입력받은 데이터에 대해 yes or no를 질의해가며 가지치기 형태로 정밀하게 분류해나가는 방식입니다. 본 튜토리얼은 파이썬 활용에 초점을 두고 있으므로 구체적인 알고리즘을 다루지는 않으니 구글링을 통해 적극적으로 찾아가며 학습하시길 권장 드립니다.
2-3. 지도학습 예측값 y 정의
자, 이제 우리는 지도학습을 수행할 것이고, 지도학습을 수행한다면 예측하고자 하는 타겟(label, y)이 필요하다는 것을 알고 있습니다. 지난 튜토리얼에서 내일의 주가는 예측할 수 없다는 결론을 내렸습니다. 과연 기계학습을 통해 주가를 예측해 보면 어떨까요? 다만, 정확한 주가를 예측하기보다 내일의 주가가 오를지, 내릴지에 대해서만 '분류'하는 것으로 테스크 난이도를 낮춰주면 좀 더 의미 있는 성과를 기대해 볼 수 있겠습니다.
파이썬의 list comprehension 문법을 통해 y를 만들어줍니다. y의 이름은 'up'입니다.
diff() 함수는 바로 직전 row(행)과 현재 row(행)의 차이를 계산합니다. 종가에 대해 diff() 함수를 수행해 주면 아래와 같이 전일 대비 즘 감음 계산할 수 있습니다.
이렇게 나온 값들을 위에서부터 아래로 순회하며 만약 값이 0과 같거나 크면 1, 그렇지 않다면 0으로 표시합니다. 이것을 labeling이라고 하며, 일반적으로 이진 분류의 경우 이렇게 1과 0으로 분류 대상을 마킹해줍니다.
결과적으로 오늘 종가가 전날 종가와 같거나 상승했다면 'up'이 1로 표기되고 그렇지 않은 경우 0으로 표기됩니다. 여기서 주의해야 할 점이 있습니다. 우리가 2010년 6월 29일의 종가와 2010년 6월 30일의 종가를 보고 y를 마킹했는데, 모델이 2010년 6월 30일의 y('up' 여부)를 예측해야 하는 상황이라면 어떤 날짜의 데이터(Close)를 보도록 해야 할까요? 다시 말해, X(변수)의 시점은 언제일까요?
2010년 6월 29일입니다. 만약, 2010년 6월 30일 데이터(X)를 보고 up(y)을 예측하도록 시킨다면 모델은 100% 확률로 모두 정답을 가려낼 것입니다. 우리가 '어제 대비 오늘 증가했는가?'를 수식으로 계산해 y를 만들었는데, 우리가 이렇게 수식을 계산할 수 있다면 모델은 너무 간단히 함수를 정의해버릴 것입니다. 사실, 이것은 오늘의 결과를 미리 보고 'up'을 예측한 것과 같고, 이를 미래 참조 편향(lookahead bias)이라고 합니다. 따라서 예측하고자 하는 대상과 예측에 사용될 변수를 이러한 오류가 없도록 설정해 주는 것이 매우 중요합니다.
다시 돌아와서, 우리는 모델 학습에 '시가, 고가, 저가, 종가, 거래량' 이렇게 5가지 feature(x, 각각의 변수)만 사용할 것입니다. 일명 캔들 차트를 구성하는 4개 요소와 일별 관심도 혹은 유입/유출량을 보여주는 거래량 정보를 가지고 다음 날의 종가 상승 여부를 예측(분류) 해보고자 합니다. 따라서 아래와 같이 인덱싱해주고, 칼럼은 소문자로 변환해 주겠습니다.
그다음, 모델이 학습할 수 있도록 X와 y를 나눠줍니다.
Step 3. 모델 인스턴스 생성 및 파이프라인 정의
3-1. 인스턴스 생성
sklearn 및 각종 패키지를 통해 모델 클래스를 불러와 각각 인스턴스를 생성해 줍니다.
3-2. 파이프라인 정의
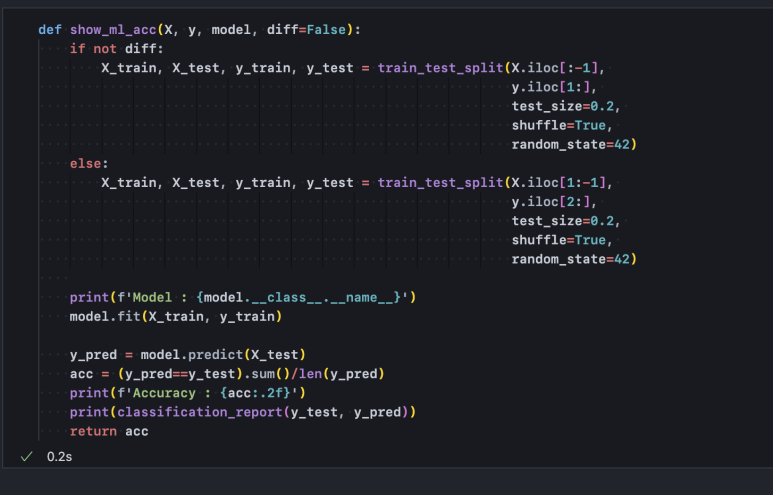
여기서 파이프라인은 모델 학습 및 평가 프로세스를 의미하며, 다음과 같은 흐름으로 진행됩니다.
- 1. X, y 데이터를 각각 학습(train)용, 평가(test) 용으로 분할합니다.
- 2. 모델은 학습 데이터로 주어진 X_train, y_train를 학습합니다.
- 3. 학습된 모델은 X_test를 평가(예측) 합니다.
- 4. 평가 결과(y_pred)를 실제 값 y_test와 비교해 정확도를 측정합니다.
이러한 프로세스를 함수로 구현해두고, 간단히 함수를 호출하는 것만으로 데이터 처리, 모델 학습, 평가까지 한 번에 수행될 수 있도록 합니다.
sklearn에서 제공하는 train_test_split() 함수는 파이프라인 중 Flow 1을 수행합니다. test_size=0.2, shuffle=True로 설정하면 전체 데이터 중 학습 데이터를 80%, 평가 데이터를 20%로 '랜덤하게'(shuffle) 추출해 줍니다. 여기서 random은 완전한 무작위 추출은 아니고, 지정한 random_state에 따라 정해진 로직으로 무작위 추출을 하게 되는데 저와 동일하게 42로 설정하면 내부적으로 동일한 알고리즘에 따라 데이터를 추출할 수 있습니다. 즉, random이라도 재실행했을 때 동일한 결과(분할된 데이터)가 나올 수 있도록 세팅되는 것입니다.
그리고 X.iloc[:-1], y.iloc[1:] 부분은 각각 분할하고자 하는 대상인 X, y를 넣어주는 곳인데, 위에서 설명한 것처럼 우리가 예측하고자 하는 타겟은 '다음 날의 종가가 올라있을지 여부'이기 때문에 X는 첫날부터 마지막 날 하루 전까지로 지정하고, y는 둘째 날부터 마지막 날까지로 설정해 주는 것입니다. 이렇게 하면 (X, y)를 (첫날, 둘째 날), (둘째 날, 셋째 날)과 같이 매칭 시킬 수 있습니다.
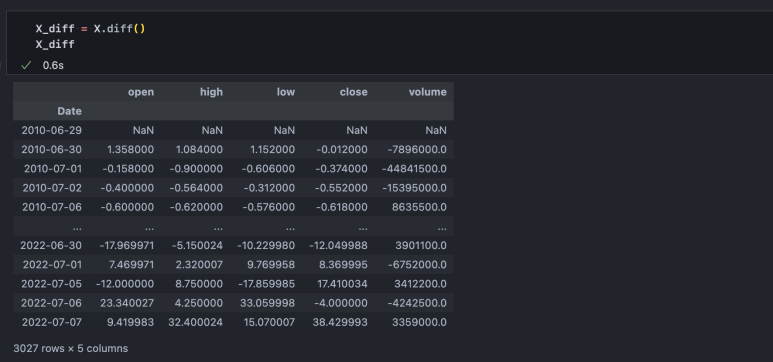
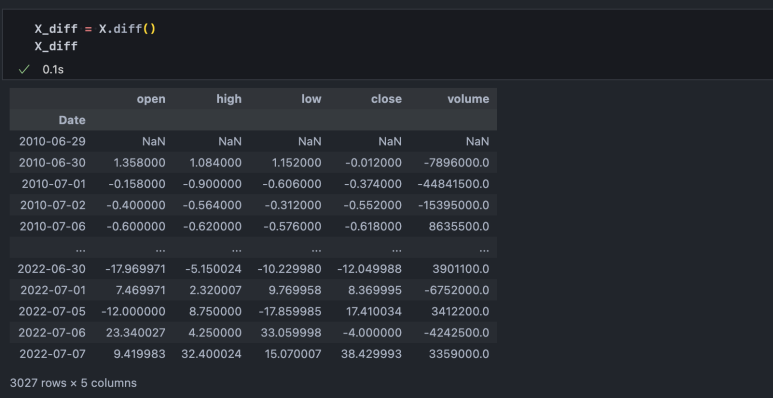
다음으로 if 함수를 통해 diff=True인 경우에는 X.iloc[1:-1], y.iloc[2:]로 설정해서 (첫날, 둘째 날)이 아니라 (둘째 날, 셋째 날)부터 데이터가 시작될 수 있도록 해줬는데, 아래와 같이 해당 함수를 사용하면 첫날의 데이터는 NaN이 되기 때문입니다.
Flow 2는 모델을 학습하는 구간, Flow 3은 평가(예측) 하는 구간입니다. 함수에서는 model.fit(X_train, y_train)과 model.predict(X_test)로 작성돼있습니다. 기계학습 모델은 데이터를 fitting(적합) 시킨 다음 predict(예측) 합니다. 이것이 함수로는 fit()과 predict()로 구현되어 있으며 우리는 이를 순서대로 실행해 주면 됩니다.
그리고 함수 인자에서 볼 수 있듯 학습할 때는 학습 데이터인 X_train, y_train을 사용하고 예측할 때는 평가 데이터인 X_test를 사용합니다. 모델이 이미 학습에 사용한 데이터(X_train)에 대한 label(y_train)를 알고 있기 때문에 예측은 X_test에 대해서만 수행하는 것입니다. 만약 train, test 데이터를 분리하지 않고 모두 학습에 사용했다면 그중 일부(예를 들면 X_test)에 대해 예측을 수행했을 때 정답(y_test)을 100% 확률로 맞춰낼 것입니다. 모델이 답안지를 미리 봤기 때문입니다.
Step 4. 모델링 및 평가
우리는 본 실습에서 3가지 형태의 데이터 셋을 학습 및 평가해 볼 것입니다. 이전 튜토리얼에서 시계열, 특히 주가 데이터를 분석할 때 차분 및 로그 차분 데이터를 사용할 필요가 있다는 점을 설명한 바 있습니다. 따라서 여기서도 원본 주가 데이터, 차분한 주가 데이터, 로그 차분한 주가 데이터를 각각 모델에 넣고 예측을 수행해 보고자 합니다.
4-1. 기본 데이터
앞서 총 4개의 모델 인스턴스를 정의했습니다. 다시 확인하겠습니다.
위 모델을 반복문을 통해 순차적으로 학습시키고, 정확도를 확인해 보도록 하겠습니다.
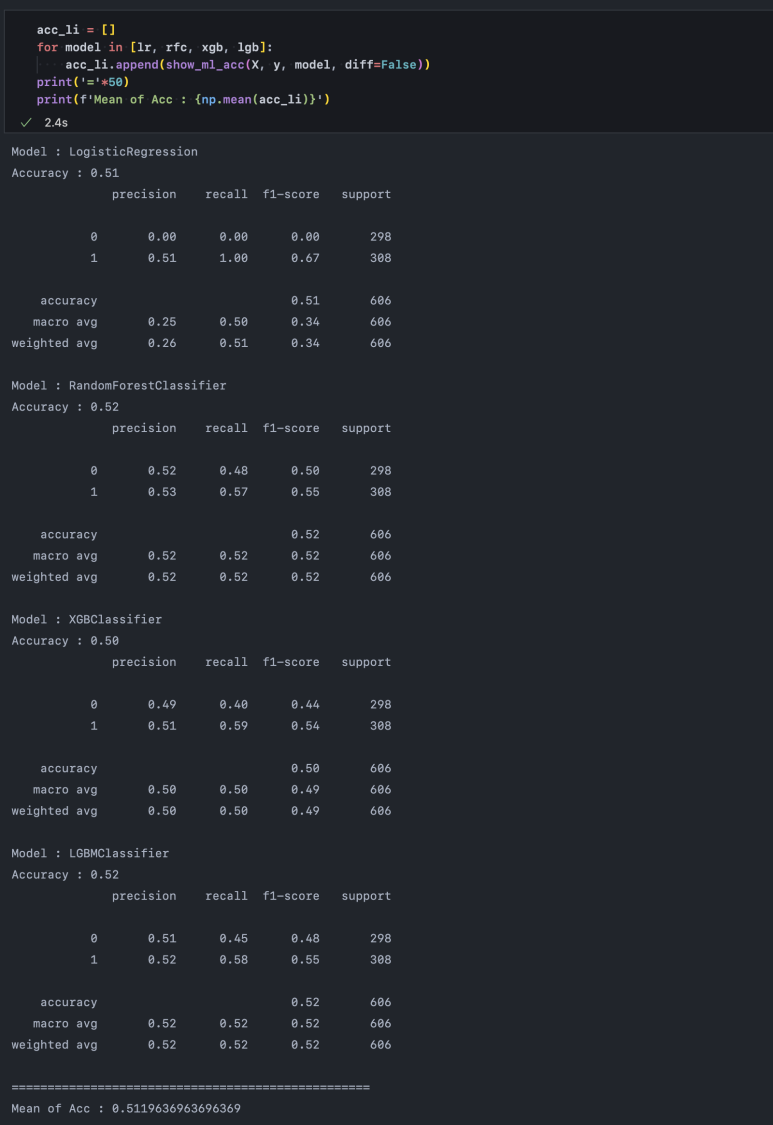
acc_li 리스트는 우리가 파이프라인으로 정의한 show_ml_acc()의 return 값인 acc를 받습니다. 모든 모델마다 acc를 받으면 총 4개의 acc가 쌓이고, 이를 평균 내서 마지막 줄에 print() 함수로 출력해 줬습니다. 그러면 해당 데이터로 모델들을 학습시켰을 때, 평균적인 정확도를 확인할 수 있습니다.
여기서 우리는 단순히 '모델 정확도가 51% 정도 되네' 하고 넘어가선 안됩니다. 더 중요한 것은 이 부분입니다.
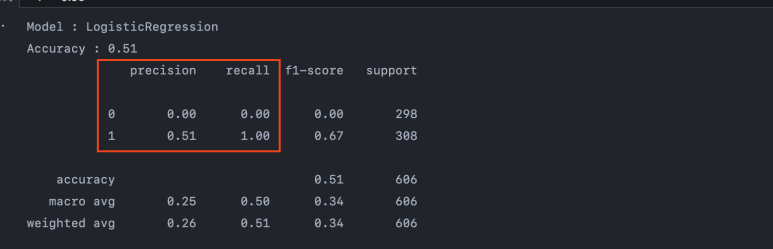
precision은 정밀도입니다. 즉, 모델이 y를 0 혹은 1이라 분류했는데, 이것이 얼마나 정밀하게 잘 들어맞는가?를 보여줍니다. LogisticRegression의 경우 모델이 1이라 예측한 것 중 실제 1인 비율이 51%네요.
recall은 재현율입니다. 실제 1이 308개(support에 표기되어 있습니다.) 있는데, 그중 몇 개나 동일하게 재현해냈는가?(맞췄는가?)를 보여주는 지표입니다. 이 경우, 308개 모두 맞췄네요.
그런데 좀 이상합니다. 0에 대해서는 모두 정확도가 0%입니다. 이것은 데이터를 들여다볼 필요가 있습니다.
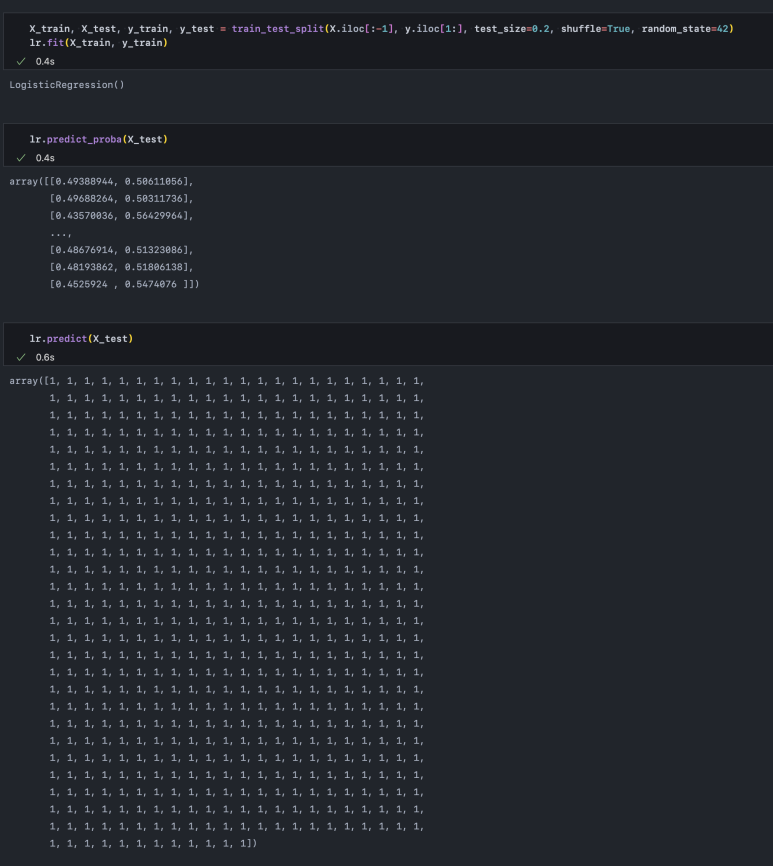
predict_proba() 함수는 각 label(0, 1)에 대해 몇 %의 확률로 실제 정답이라 예측하는지 알려주고, predict() 함수는 그러한 예측 확률에 의해 나온 예측 결과를 1차원 배열로 이어서 보여줍니다. 보시면 모두 1로 예측한 것을 알 수 있습니다.
모델 정확도를 대표하는 Accuracy는 0을 0이라 하고, 1을 1이라 예측한 것의 비율을 보여줍니다. 그래서 단순히 Accuracy만 본다면, LogisticRegression의 경우 모두 1로 예측했기 때문에 전체 데이터 606개 중 308개를 맞추고 298개를 틀렸으니 51%의 정확도가 나오는 것입니다. 따라서 우리는 precision과 recall을 잘 살펴봐야 하는 것입니다. 특히 주가 예측의 경우 모델이 예측해서 특정 action을 취했는데 모델이 오답을 낸 경우 매우 큰 리스크를 지게 됩니다. precision이 더 중요한 task라는 의미입니다. 일반적으로 모델이 특정한 균형 상태에 도달했을 때, trade-off 관계인 precision과 recall을 동시에 높이기는 어렵기 때문에 한쪽의 성능을 최대한 끌어올리는 방향으로 최적화를 하게 되는데, 암 진단이나 지금의 주가 예측같이 '오답 시 리스크'가 큰 경우는 precision을 높이고, 사기 탐지나 코로나 검사처럼 '발견 실패 시 리스크'가 큰 경우는 recall을 높입니다.
그러나 이렇게 한쪽이 극단적으로 높거나 낮게 되면 해당 모델에 적합하지 않은 데이터 분포를 사용했거나, 모델 자체가 현재의 Task에 적합하지 않은지 의심해 볼 필요가 있습니다. LogisticRegression은 선형회귀를 기반으로 하기 때문에 비선형 구조의 복잡한 패턴을 찾는 데에는 어려움이 있습니다. 따라서 데이터의 복잡도를 낮춰주는 방향으로 개선하거나 비선형 모델링이 가능한 다른 모델을 사용해야 합니다.
트리 기반 알고리즘은 복잡한 데이터를 단순한 로직으로 잘 학습하는 대표적인 모델입니다. 아래와 같이 precision과 recall 모두 안정적으로 확인되며 특히 y=1에 대한 정밀도(precision)을 보면, '상승하는가?'에 대해서는 '찍기'보다 조금 나은 0.51~0.53 정도의 정확도를 보여주고 있습니다.
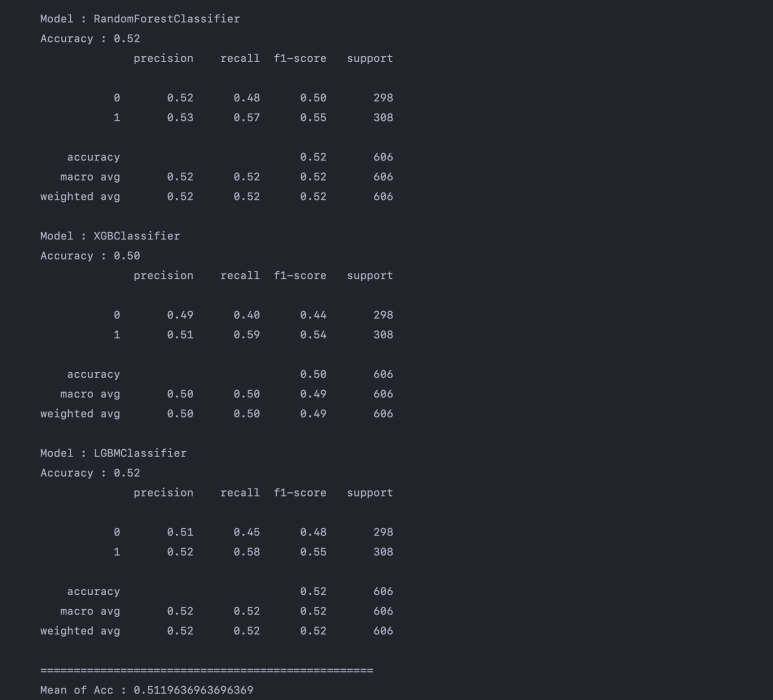
4-2. 차분 데이터
그렇다면, 데이터 복잡도를 낮춘 차분 데이터는 어떨까요? 차분을 수행하면 '어제 대비 오늘의 증감'으로 데이터를 단순화시킬 수 있고, 해당 데이터로 내일의 상승 여부를 예측하는 Task가 됩니다.
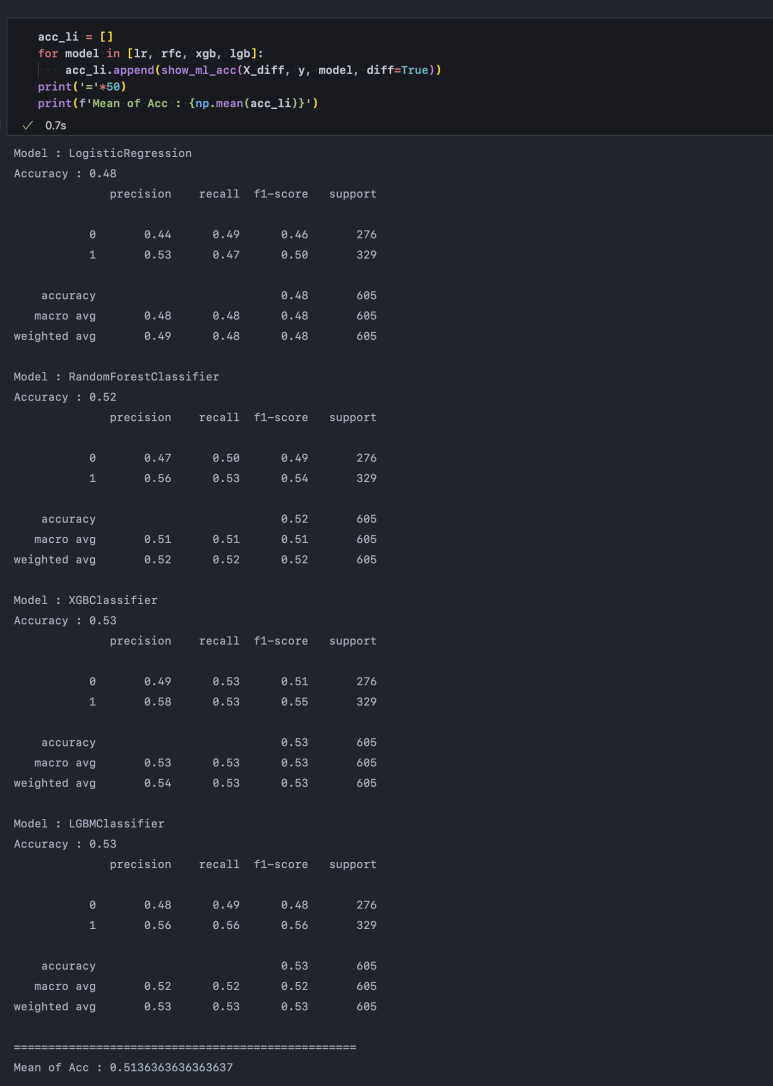
이렇게 성능은 타 모델 대비 좋지 않은 편이지만 차분을 해주는 것만으로도 LogisticRegression의 성능을 높여줄 수 있습니다. 그러나 데이터 복잡도가 낮아지면 트리 모델의 성능은 위와 같이 상대적으로 더 높아지기 때문에 해당 Task에 LogisticRegression를 굳이 사용할 이유는 없겠습니다.
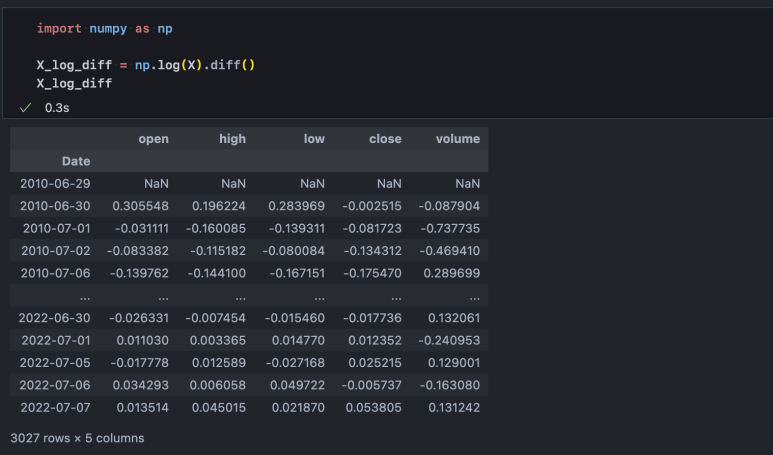
4-3. 로그 차분 데이터
데이터에 로그를 씌우고 차분해주면 추세나 계절성 등의 규칙적인 움직임은 대부분 사라지고 그러한 움직임에 내재된 불규칙한 패턴만 남게 됩니다. 차분을 해준다는 점에서 복잡도를 덜어낼 수 있지만 로그가 비선형 함수이기 때문에 LogisticRegression은 이번에도 역시 고전을 면치 못할 것입니다.
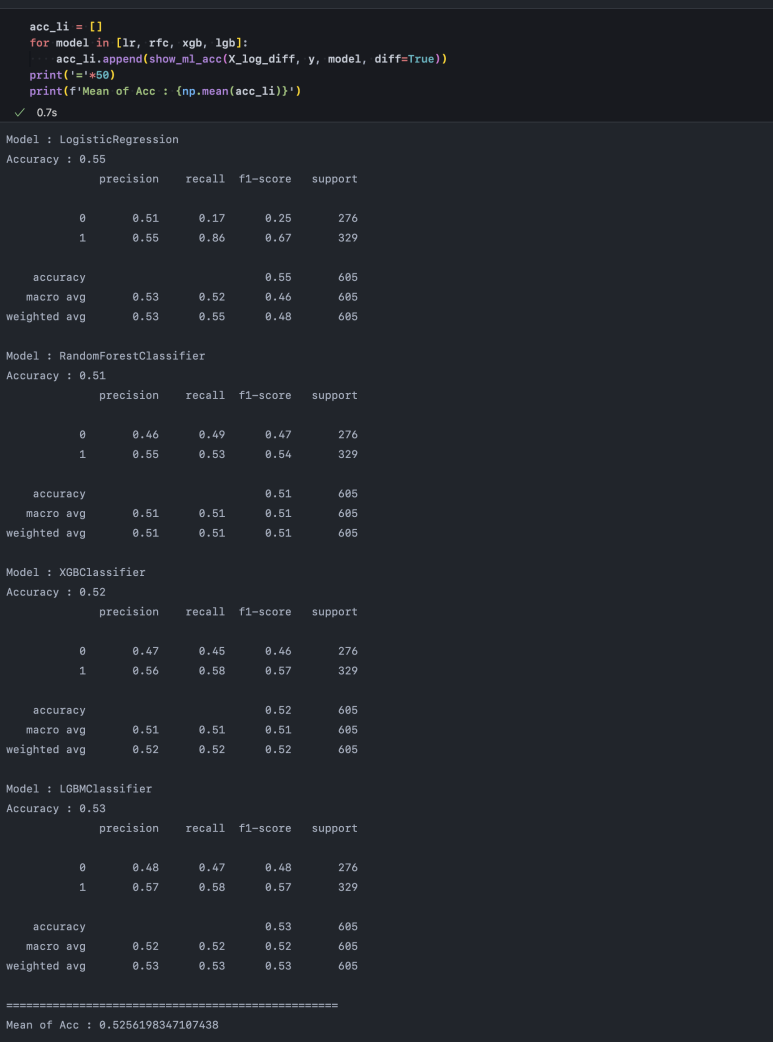
LogisticRegression의 Recall이 기본 데이터를 사용했을 때와 비슷하게 대부분 1(up)로 예측을 해버렸네요. 이렇게 비선형 처리가 들어가게 되면 선형회귀 기반의 함수는 관측치를 제대로 설명하기 어려워집니다.
반면, 나머지 트리 기반 모델들도 이전보다 성능이 좋진 않습니다. 주가에 로그 차분을 수행했을 때, 너무 많은 정보 손실이 발생했기 때문입니다.
이처럼, 아주 간단한 모델링에도 신경 쓸 부분이 많습니다. 기계학습이 정말 기계적으로 알아서 분석하고 예측해 주면 좋겠지만, 모델이 어떤 원리로 동작하는지 이해하고 해석해 보면서 적합한 데이터 처리 과정을 수행해 줘야 제대로 된 예측 및 분류 모델을 개발할 수 있습니다. 그러나 동시에 아무리 복잡한 데이터라도 기계학습 알고리즘을 사용하면 유의미한 관계식을 구현할 수 있다는 점은 대단한 가능성을 열어줍니다. 따라서 이러한 알고리즘을 간단히 구현할 수 있게 도와주는 파이썬이라는 도구는 우리가 데이터를 다루고자 한다면 능숙하게 다뤄야 하며, 몸에 익을수록 더 큰 효용을 가져다줄 것입니다.