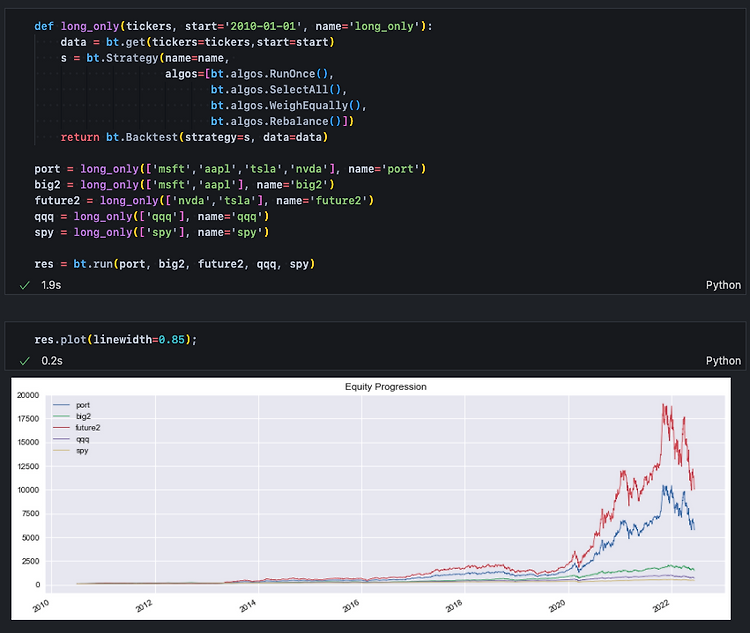
background Conditional GAN - latent vector(random)와 함께 Condition(y)을 받을 수 있다(무작위가 아닌 목표로 하는 이미지를 생성) pix2pix - 이미지(X, Condition)를 받아서 이미지를 돌려준다. y(label, condition)를 따로 받는 것은 아니지만 X 자체를 Condition으로 입력 받아 목표로하는 이미지를 생성하기 때문에 Conditional GAN에 기반을 둔다고 볼 수 있다. CycleGAN , StarGAN은 모두 Conditional GAN 기반의 pix2pix 구조를 사용한다. CycleGAN은 이미지를 받아서 이미지를 돌려주고, StarGAN은 이미지와 y(도메인 Vector)를 추가로 받아서 y에 맞는 이미지를 돌려..