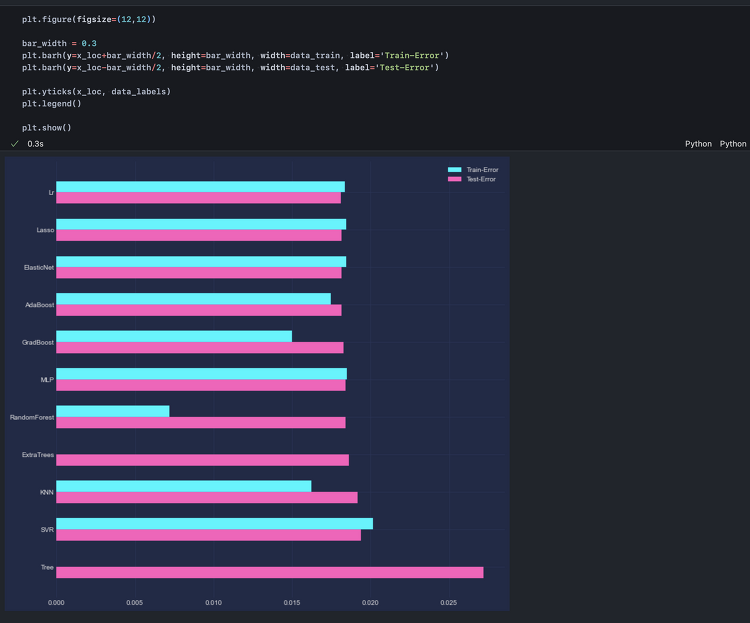
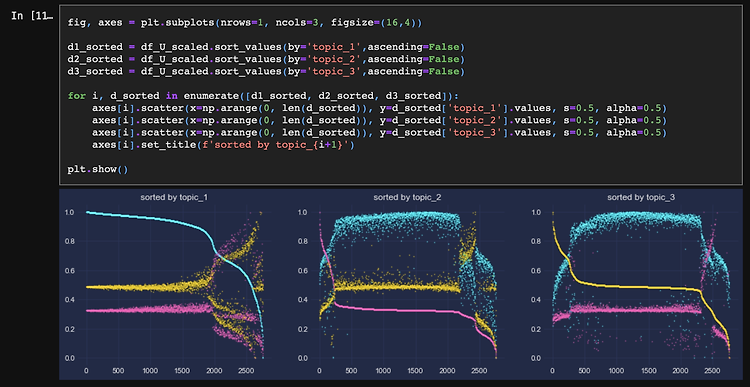
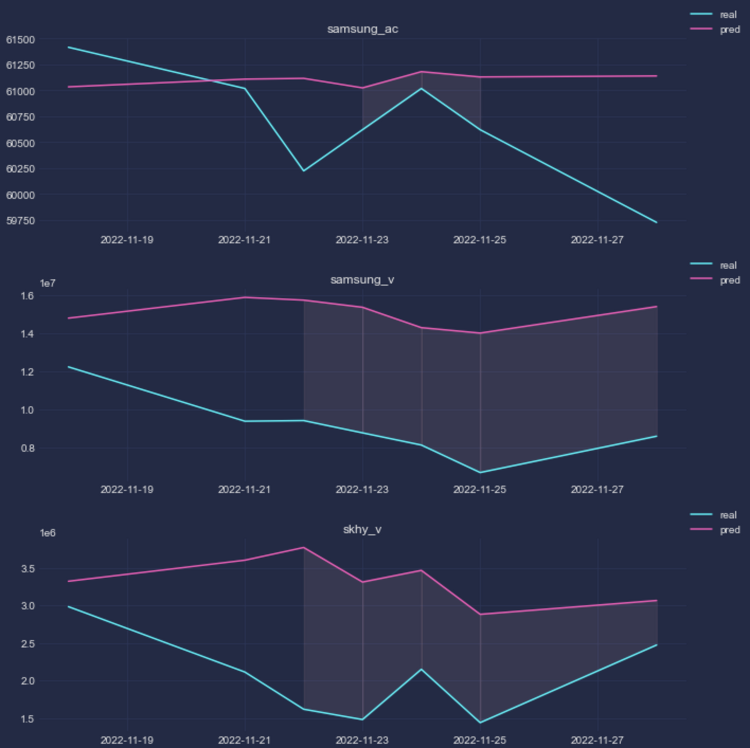
본 글에서는 ARIMA 모형을 활용해 미래 미국채 Spread 추이를 continuous하게 예측하고, 이어서 Probit 모형을 통해 ARIMA 예측값을 경기침체 여부로 변환한다. 경제 예측 모델링을 수행할 때에는 가급적 단순한(파라미터가 적은) 모델, 해석가능한 모델을 사용하는 것이 좋다. 일반적인 인식과 달리 경제 데이터는 딥러닝과 같은 모델 아키텍처로 적합시킬 만큼 대용량이 아닐 뿐더러 제대로 적합되지 않았을 때 Fat Tail Risk가 미치는 영향이 치명적일 수 있기 때문이다.따라서 시계열 모델 파라미터를 분리 해석할 수 있는 ARIMA 모형, 종속변수가 binary(이진) 변수일 때 yes or no 에 대한 발생 확률을 가장 단순하게 설명가능한 Probit 모형을 사용하고, 이를 통해 현재..