데이터를 시각화하는 도구는 여러 가지가 있습니다. 특히 시계열 데이터의 경우 엑셀이나 스프레드시트, PPT만으로도 충분히 의도하는 내용을 차트로 만들어낼 수 있습니다. 따라서 '굳이' 파이썬으로 시각화를 하고자 한다면 단순히 파이썬으로 분석, 시각화까지 이어서 진행할 수 있는 연속성 외에도 파이썬이 주는 자유도와 자동화로 인한 편의를 충분히 활용해야 합니다.
파이썬을 사용하면 반복문과 함수를 손쉽게 활용하고, 프로그래밍을 통해 여러 차트를 동시에 그려낼 수 있습니다. 이를 극대화해주는 함수가 subplots()입니다.
Step 1. 레이아웃 설정
먼저, matplotlib.pyplot 패키지를 plt라는 이름(alias, 별칭)으로 불러옵니다.

plt를 통해 아래와 같이 전체 레이아웃을 subplot으로 분할하고, 특정 subplot에 그래프를 그릴 수 있습니다.
코드 흐름은 아래와 같습니다.
- 먼저 전체 레이아웃을 figsize=(12,12)로 설정해서 가로, 세로가 동일(12)한 사이즈의 공간을 마련합니다.
- 공간을 3행 2열의 작은 subplot으로 나눠주고, 각 subplot에는 axes 변수로 접근할 수 있도록 합니다.
- np.linspace(1, 10, 10)으로 1부터 10까지 10(3번째 인자)개 구간으로 나눠 데이터를 생성합니다. 그럼 data_x에는 array([1,2,3,4,5,6,7,8,9,10]) 이 들어가고, 각 요소의 타입은 float입니다.
- data_y는 data_x의 모든 요소에 대해 2승한 값을 넣어줍니다.
- data_x, data_y로 첫 번째 행, 첫 번째 열에 위치한 subplot axes[0,0]에 차트를 그려줍니다.
- 해당 subplot에는 set_xlabel(), set_ylabel() 함수로 각각 x축 이름, y 축 이름을 설정해 주고, set_title() 함수로 subplot 이름을 해당 subplot 상단에 표시해 줍니다.
- 첫 번째 행, 두 번째 열에 위치한 subplot axes[0,1]에는 위 방식으로 차트를 그리되, data_y는 data_x 요소들을 모두 3승한 값을 넣어줍니다.
- 마지막으로 plt.show() 함수로 전체 subplot을 함께 그립니다.
Step 2. 반복문 활용
그런데, 이런 방식으로 6개의 subplot을 모두 그리기에는 너무 번거롭습니다. 따라서 우리는 반복문을 사용해 1~10까지의 정수(float type이지만 소수점 이하 0을 생략하여 정수라는 표현을 사용하겠습니다.)를 2승, 3승 ~ 7승한 그래프를 각 subplot에 순서대로 그려보겠습니다.
axes.shape이 (3,2)이므로 a*b는 6입니다. 따라서 for i in range(a*b) 반복문을 통해 i는 0부터 5까지 1씩 증가합니다. i가 1씩 증가하면 i를 2로 나눈 몫은 순서대로 0, 0, 1, 1, 2, 2가 되고, i를 2로 나눈 나머지는 0, 1, 0, 1, 0, 1이 됩니다. 둘을 각각 행의 번호, 열의 번호로 지정하고, 첫 번째 subplot부터 마지막 subplot까지 순회하며 차트를 그려나갑니다.
Step 3. 영역 채우기
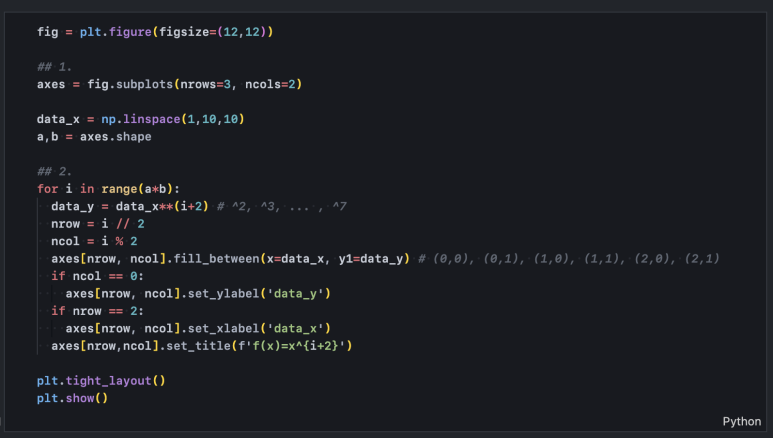
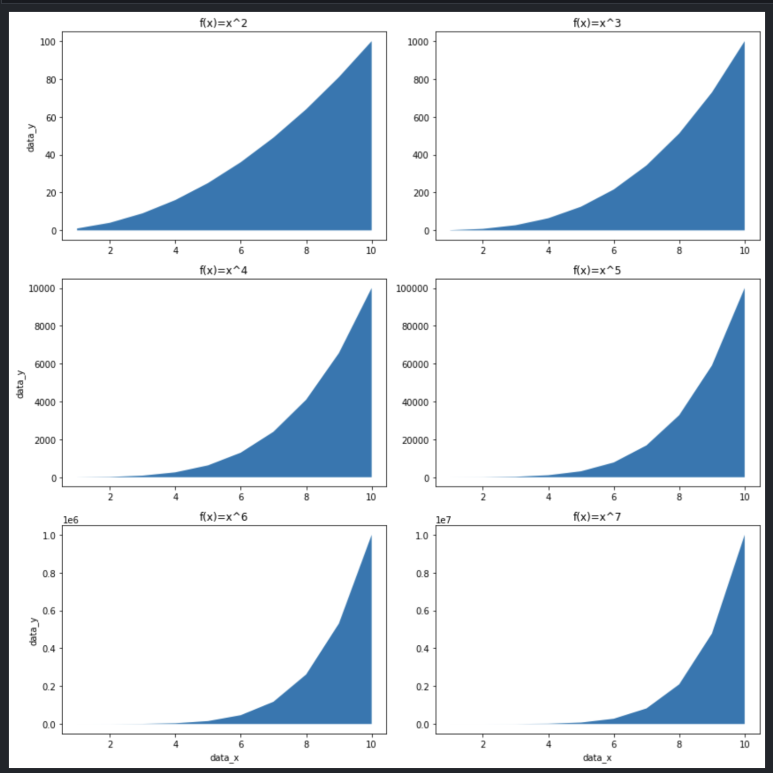
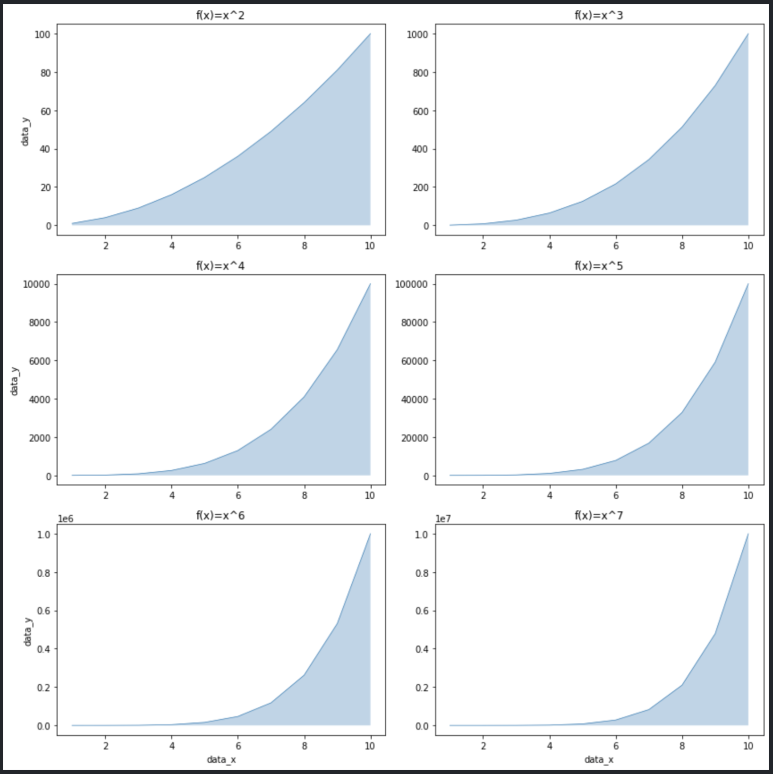
차트에 선 하나만 있을 때는 시각적으로 잘 표현되지만 2개 이상의 선을 그려야 할 때는 선 대신 면을 활용하면 좋습니다. 이때는 plot() 대신 fill_between() 함수를 사용합니다. 영역을 채우는 함수이므로 y 기준선은 y1, y2 두 개를 설정해야 하는데, y2는 default가 0이므로, 아래와 같이 y1만 설정하면 선 아래 영역을 채울 수 있습니다.
step 2와 동일한 코드에 plot() 부분만 변경합니다.
Step 4. 흐리게 표현하기
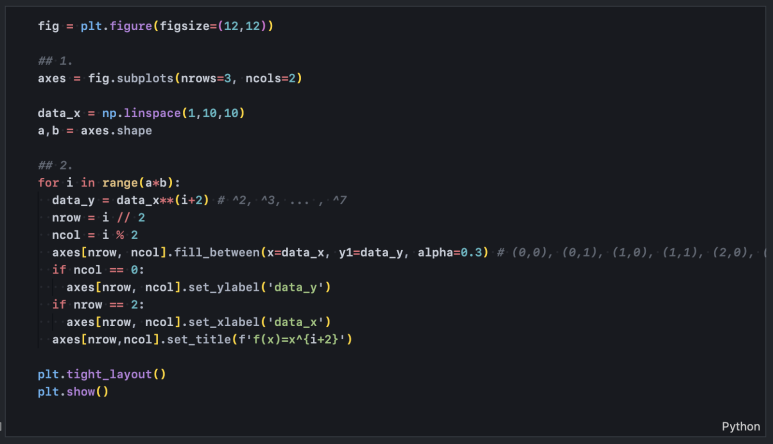
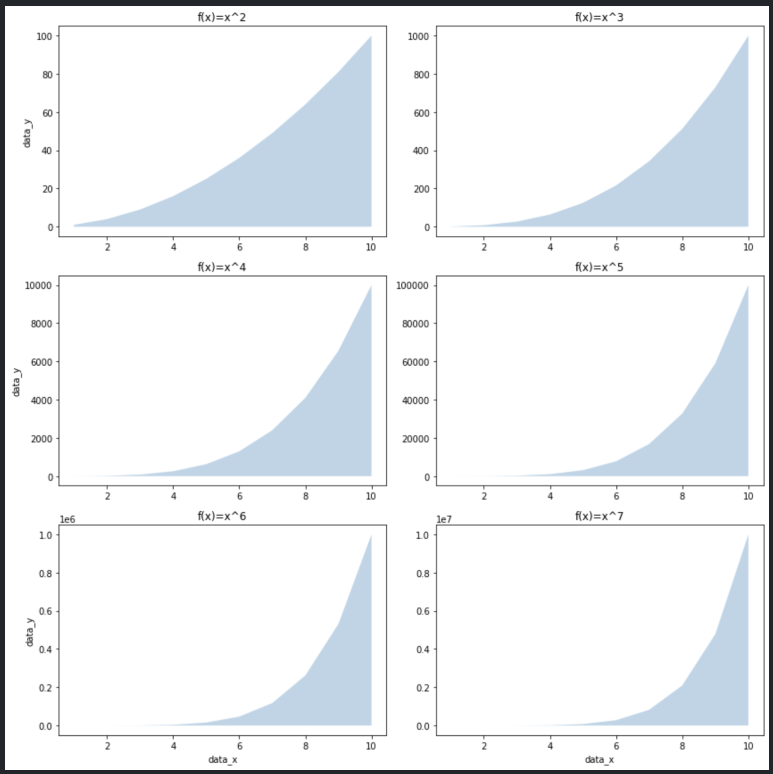
matplotlib을 사용해 그래프를 그릴 때는 일반적으로 alpha 옵션을 통해 흐리기를 지정할 수 있습니다. 0에서 1까지의 숫자로, 1에 가까울수록 색상이 짙습니다. fill_between() 함수 역시 alpha 옵션을 지원합니다.
alpha=0.3 정도로 영역을 흐리게 표현해주면 추후 선이나 면을 추가로 겹쳐 그리더라도 시각적으로 잘 나타낼 수 있습니다.
Step 5. 선과 영역을 같이 표현하기
선을 강조하고 싶은 경우 fill_between() 함수와 plot() 함수를 함께 사용하면 됩니다.
Step 6. 강조선 표시하기
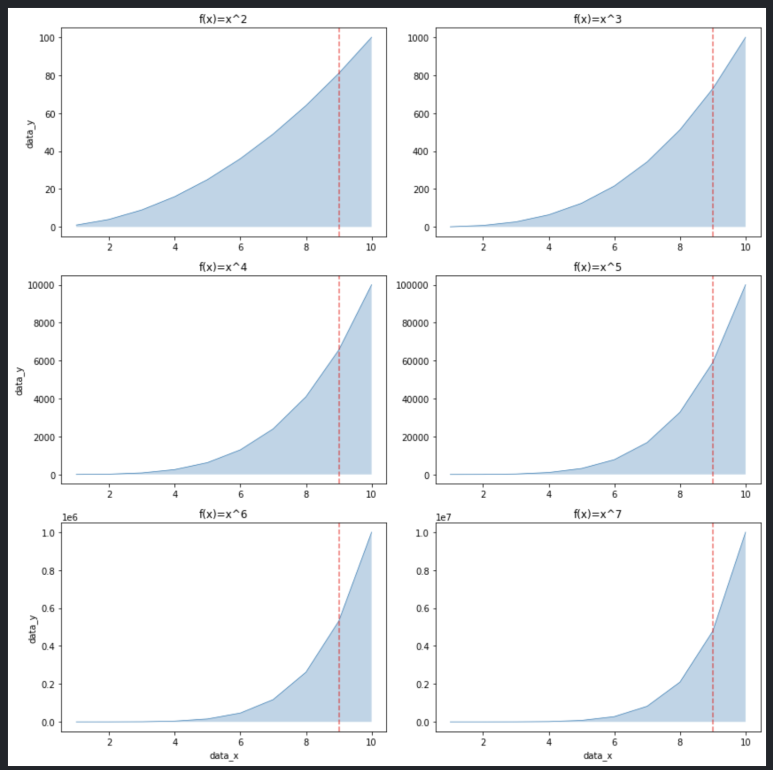
강조선은 axvline(), axhline()을 통해 표시할 수 있습니다. 각각은 ax + vertical + line, ax + horizontal + line의 약자로 수직선, 수평선을 의미합니다.
여기서도 옵션을 지정할 수 있습니다. 색상은 red로, 선 스타일은 '--'로, 흐리기는 0.6으로 설정했습니다.
Step 7. 강조 영역 표시하기
강조 영역은 axvspan(), axhspan() 함수를 사용해 표시할 수 있습니다. 각각 함수명에서 v와 h가 의미하는 바는 강조선 함수와 동일하게 vertical, horizontal이므로 기억하기 쉽습니다.
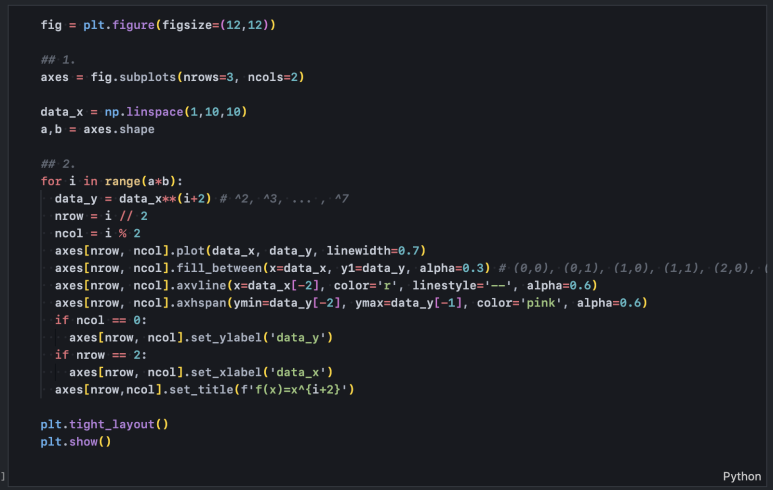
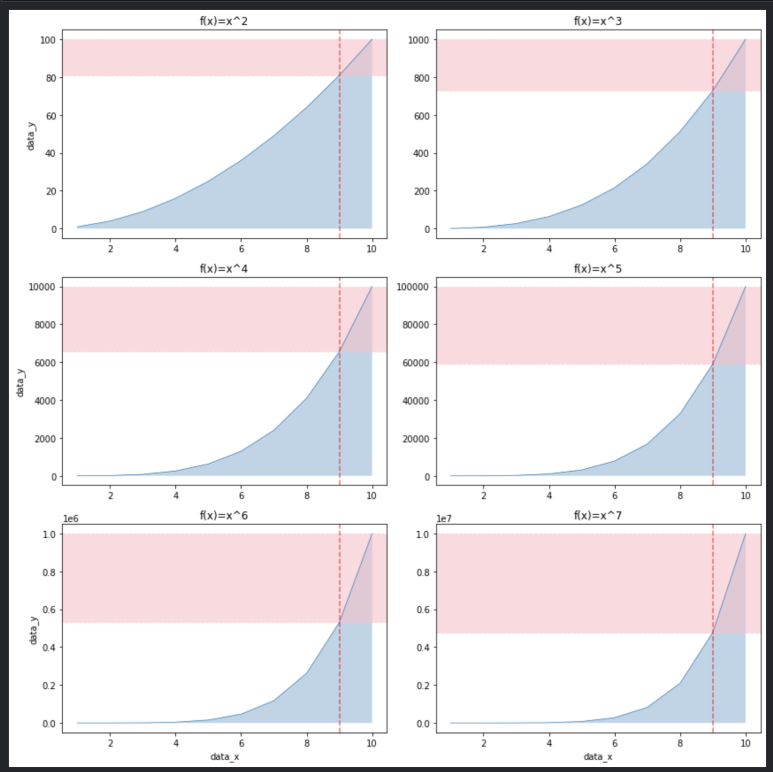
Step 8. 활용
앞서 확인한 내용들을 종합 정리하면 다음과 같습니다.
- subplots() 함수를 통해 전체 레이아웃을 행과 열로 n등분합니다.
- n등분한 레이아웃이 2차원인 경우 axes[nrow, ncol], 1차원인 경우 axes[n]로 접근하며 plot() 혹은 fill_between() 함수로 선이나 면을 그립니다.
- 이어서 axvline(), axhline(), axvspan(), axvspan() 함수로 강조선 혹은 강조 영역을 더 그려줄 수 있습니다.
- 각 그래프에 대해 alpha로 흐리기 정도를 지정하고, linestyle로 선 스타일을 지정할 수 있으며 이외 옵션들도 색상 등 다양하게 설정할 수 있습니다.
- 각 그래프에 대해 x축 이름, y축 이름, 그래프 이름을 설정할 수 있습니다.
- 마지막으로 plt.show()로 전체 레이아웃을 한 번에 그려줍니다.
우리는 위 내용을 활용해 각 연도별 테슬라 주가의 평균치 영역을 그려볼 수 있습니다.
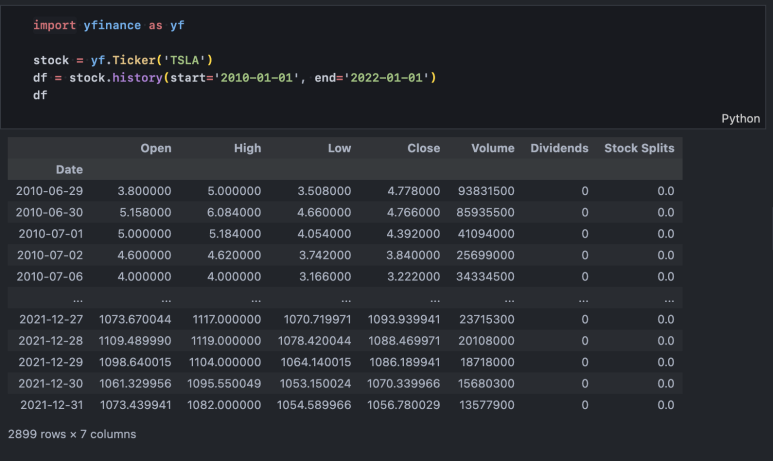
8-1. 테슬라 주가 가져오기
yahoo finance 패키지를 활용해 2010년(상장 연도) ~ 2021년 말까지의 주가 정보를 수집합니다.
8-2. 연도별 주가 평균 영역 시각화
차트를 그릴 대상은 2010년, 2018년, 2021년 3개 연도의 종가(Close) 데이터입니다. 시계열 데이터의 경우 index의 type이 datetime이라면 간단히 df['2010']와 같이 인덱싱해주면 해당 연도의 데이터를 모두 가져올 수 있습니다. 3개 연도 데이터를 각각의 subplot에 그릴 것이므로 3개 행, 1개 열을 지정해주고, axes[n]으로 접근합니다.
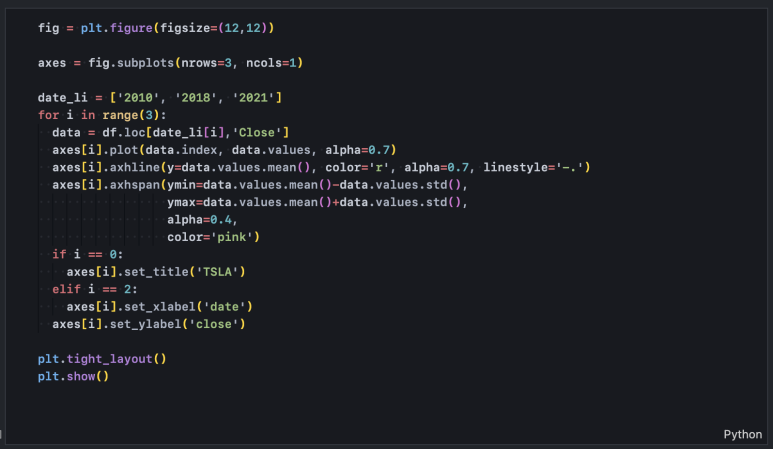
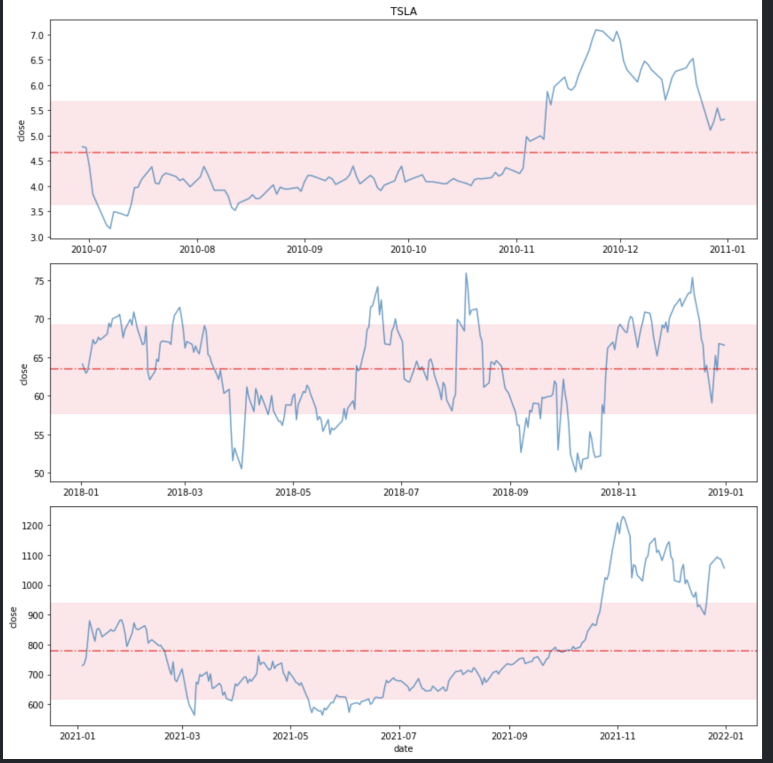
이렇게 단순히 연도별 평균만 강조선으로 그리기보다 평균 +/- 표준편차를 표시해 줌으로써 특정 날짜의 주가가 연도별 평균치를 유의미하게 상회하는지, 하회하는지를 확인할 수 있습니다.