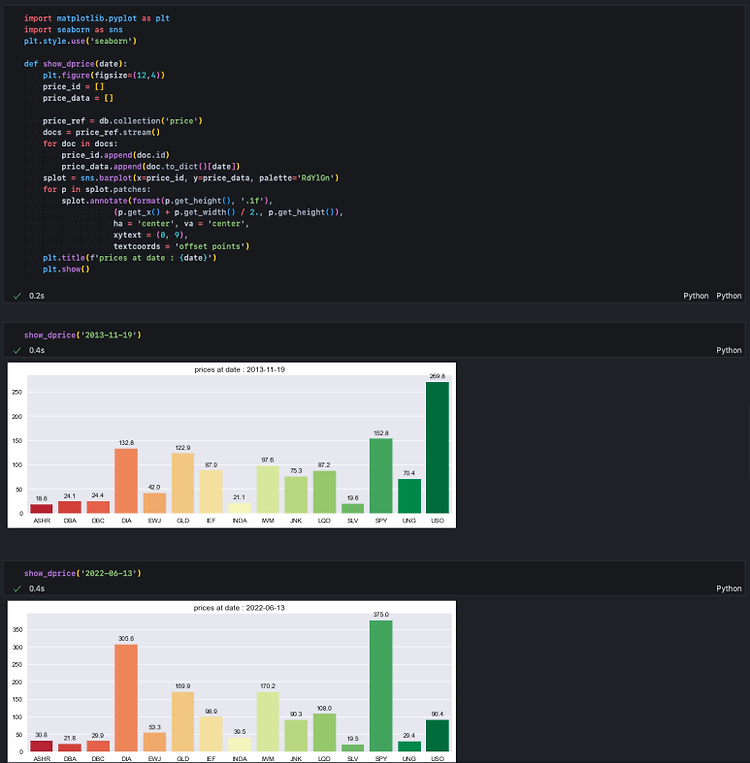
Step 1. 라이브러리 우리가 개발을 할 때, 모든 코드를 한 땀 한 땀 장인의 정신으로 구현해야 한다면 실력과 무관하게 금세 지쳐버릴 것입니다. 우리가 작성하려고 하는 코드가 매우 정형적이고 일반적으로 자주 쓰이는 것들이라면 누군가는 반드시 함수나 클래스 형태로 이미 구현해두었을 것입니다. 그리고 우리는 이것을 라이브러리라는 형태로 가져와서 쓸 수 있습니다. 심지어 무료로 말입니다. 야후 파이낸스에 있는 주가 정보도 라이브러리라는 것을 사용하면 손쉽게 가져올 수 있습니다. 누군가 이미 그러한 작업을 한 적이 있고, 개발한 코드를 모두가 사용할 수 있게 공개해둔 것이지요. 참고로 아래 이미지, 깃허브라는 코드 저장소에서 실제 구현된 코드를 눈으로 볼 수도 있습니다. yfinance라는 이름의 라이브..