파이썬에는 여러 가지 자료형, 즉 데이터 타입이 존재합니다. 그중에서도 우리는 단일 데이터를 표현해 주는 int, float, bool, str(엄밀히 말하면 연결된 char입니다만 char 자료형은 현 단계에서 접할 일이 많지 않습니다. 그래서 문자열 str을 단일 데이터 표현형으로 대체합니다.)과 다중 데이터를 표현해 주는 list, dict, set, 그리고 마지막으로 벡터 및 행렬 표현을 위한 numpy, pandas까지 빠르게 다뤄보도록 하겠습니다.
Step 1. 단일 데이터 표현
1-1. int
int 자료형은 정수를 표현할 수 있습니다. 변수에 1이나 2와 같은 정수를 담아주면 파이썬은 해당 변수의 자료형을 int로 인식합니다.

print() 함수로 변수가 가리키는 데이터를 출력할 수 있고, type() 함수로 해당 데이터의 자료형을 확인할 수 있습니다.
정수끼리 더했을 때도 역시 자료형이 정수로 동일해야 하겠죠.
1-2. float
float 자료형은 실수를 표현할 수 있습니다. 마찬가지로 print(), type() 함수로 데이터와 자료형을 확인할 수 있습니다.
덧셈도 동일합니다.
만약 실수를 정수로 바꾸고 싶다면 int()로 감싸주면 됩니다. 파이썬에서는 이렇게 간편하게 자료형을 변경할 수 있습니다.
이때, 0. 이하 숫자는 반올림되는 것이 아니라 '버림'(소거) 됩니다.
또한, 실수를 1.0과 같이 정수로 떨어지게 만든다고 해서 자료형이 바뀌지는 않습니다. 원하는 자료형으로 만들어주려면 형 변환을 직접 수행해 주어야 합니다.
1-3. str
위에서 만든 변수 a, b의 자료형은 int였습니다. 이것을 float이 아니라 문자열 str으로도 형 변환할 수도 있습니다.
만약 a, b 모두 문자열 타입으로 바꿨다면 둘을 더했을 때 3이 아니라 '12'가 됩니다. 문자열끼리 더해주면 서로 연결되기 때문입니다.
공백 문자도 문자열입니다. 추후에 데이터 분석을 직접 수행하게 되면 NA, NULL, NaN 등 다양한 공백 표현을 다루게 됩니다. 그때 이러한 공백 문자들을 특정 숫자로 치환하거나 NaN으로 변환해 주는 작업들을 자주 접할 것입니다.
1-4. bool
불리언(bool) 타입은 True or False 이진 분류형 자료형입니다. 엑셀이나 스프레드시트에서 체크박스가 바로 이런 자료형으로 동작합니다.
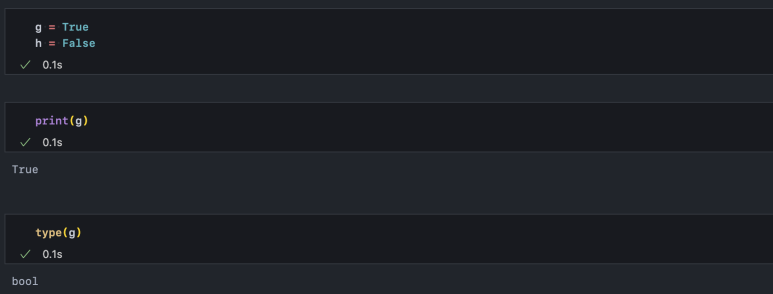
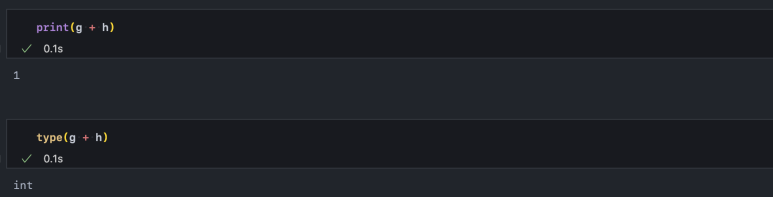
이 자료형은 int로 변경 시 True는 1로, False는 0으로 바뀝니다.

또한, 형 변환 없이 덧셈을 수행해도 1로 바뀌고 자료형도 int로 변경됩니다.
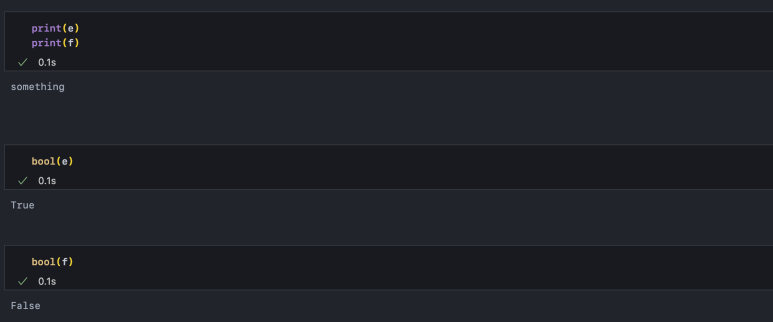
위에서 공백 문자열 ''를 f 변수에 담았습니다. 이것은 bool형 변환 시 False가 됩니다. 반대로 문자열이 공백이 아니라면 True가 됩니다.
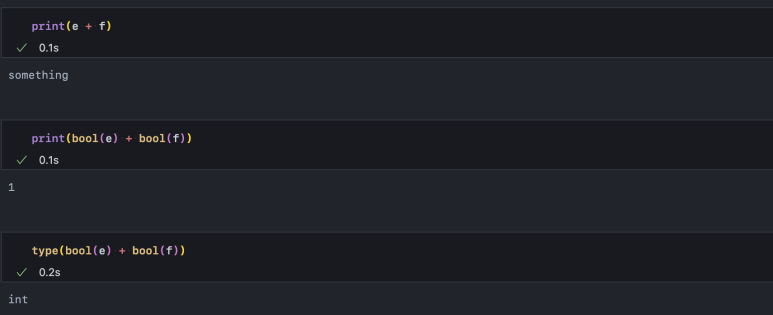
bool 자료형을 더했을 때는 int로 형 변환이 되므로 아래와 같은 결과도 자연스럽게 예상해 볼 수 있습니다.
Step 2. 다중 데이터 표현
위에서 본 데이터들을 그룹으로 묶어낼 수 있는데 대표적으로 list(리스트), dict(딕셔너리), set(세트, 집합)이 유용하게 쓰입니다.
2-1. list
먼저 리스트 자료형은 대괄호를 통해 여러 요소들을 1차원 배열로 묶어줍니다. 이때, 요소들이 꼭 동일한 자료형일 필요는 없습니다. 리스트끼리 더해주면 문자열처럼 연결됩니다.
사실, 앞서 언급했듯 문자열 str은 메모리 참조 구조로 볼 때, char의 배열입니다. 따라서 문자열을 list로 형 변환해 주면 각 문자가 리스트 원소가 됩니다. 단, 이때 각 문자의 자료형은 문자열입니다.

2-2. dict
다음은 딕셔너리입니다. 딕셔너리는 명칭처럼 키와 값으로 이루어진 사전과 같습니다. 아래 예시에서 'a'와 'b'는 키, 그리고 각각의 키에 대한 값은 li_a, li_b가 됩니다.
사전에서 'a'키에 들어있는 값을 조회하고 싶다면 대괄호를 통해 인덱싱할 수 있습니다.
두 값은 모두 리스트 자료형이기 때문에 더했을 때 아래와 같이 연결되어야 합니다.

2-3. set
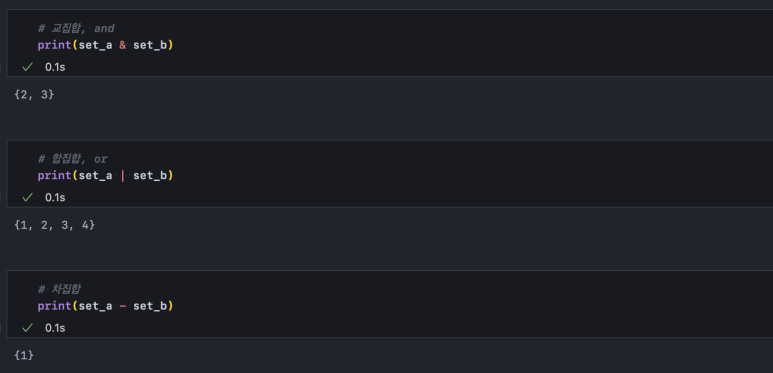
set은 집합입니다. 딕셔너리와 동일하게 중괄호로 생성할 수 있습니다.
자료형 특성상 교집합, 합집합, 차집합을 수행할 수 있으며 리스트가 아니므로 합집합에 더하기 기호는 사용할 수 없습니다.
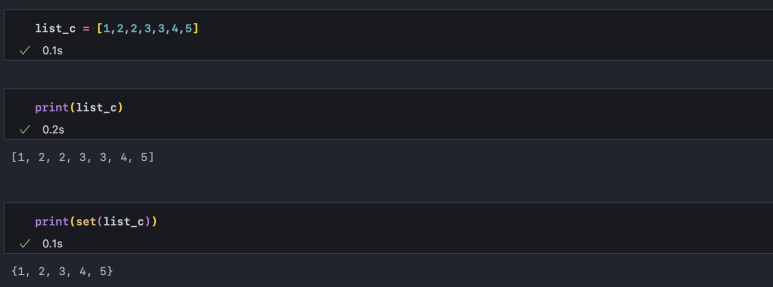
집합은 중복이 제거된다는 특성이 있습니다. 만약 중복 원소를 포함한 리스트를 집합으로 바꾸면 아래와 같이 중복이 제거됩니다. 이 방식은 간단하지만 unique 한 원소를 추출할 때 유용하게 쓰입니다.
Step 3. 벡터 및 행렬 표현
3-1. numpy array
파이썬에서는 벡터 및 행렬 연산을 위해 numpy라는 외장 라이브러리를 사용할 수 있습니다. 먼저, numpy를 np라는 별칭으로 불러옵니다.(라이브러리에 대한 설명은 다음 챕터(01)에서 확인하실 수 있습니다.)

이제 1차원 배열, 혹은 벡터 array를 생성하고 출력해 보겠습니다.
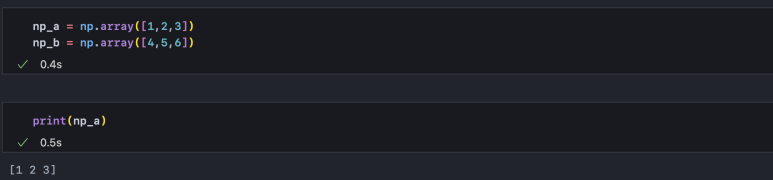
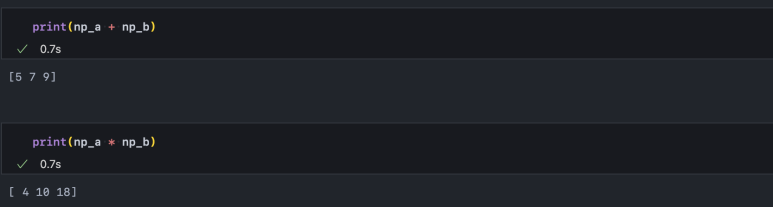
겉보기에 list 자료형과 동일해 보입니다. 하지만 np_a와 np_b를 더하거나 곱해보면 리스트와 달리 벡터 연산이 되는 것을 확인할 수 있습니다.
np.dot() 함수를 사용하면 행렬 곱도 수행할 수 있습니다.

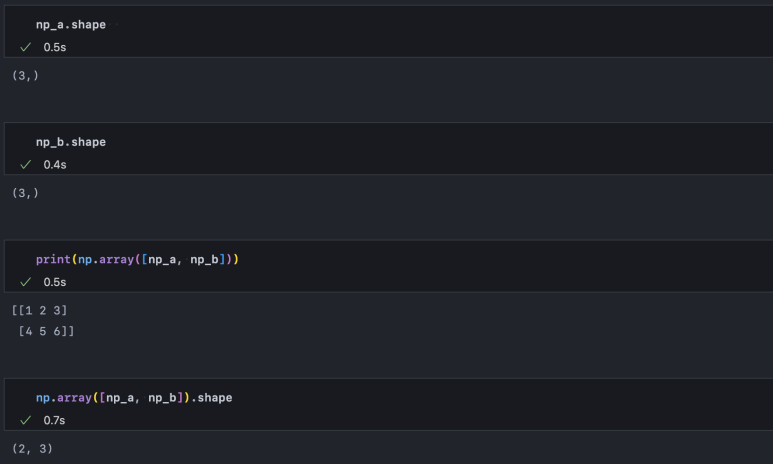
shape을 출력해 보면 벡터 혹은 행렬 크기를 확인할 수 있습니다. 1차원 벡터라면 (n, ) 형태로 출력되고 2차원 행렬이라면 (n, m) 형태로 출력됩니다. 아래 예시에서는 np_a, np_b 두 벡터를 다시 한번 np.array()로 묶어 2차원 행렬로 변환해 shape을 출력하는 모습을 보여주고 있습니다.
3-2. pandas DataFrame, Series
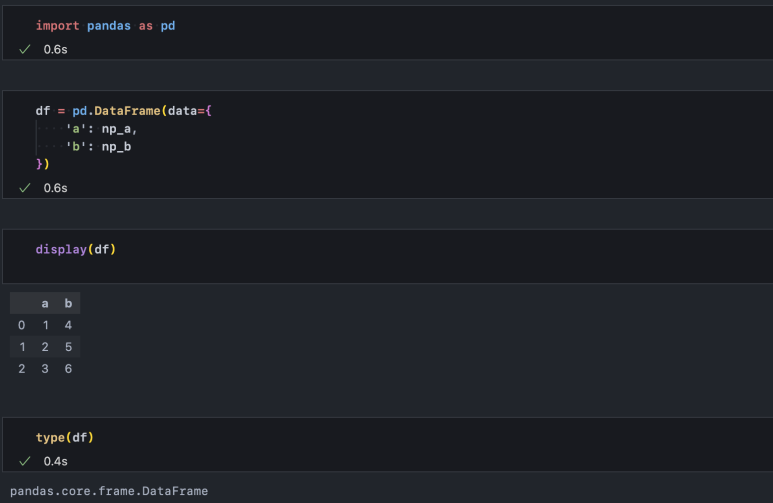
판다스는 1차원 벡터를 Series 자료형으로, 2차원 행렬을 DataFrame 자료형으로 나타내줍니다. 물론 numpy를 사용한 벡터, 행렬이 아닌 list나 dict 자료형을 활용해서 Series, DataFrame을 만들 수도 있습니다.
DataFrame은 엑셀이나 스프레드시트처럼 테이블 형태로 데이터를 조합해 주고 해당 툴에서 함수 수식을 통해 group_by, aggregation 등을 수행한 것처럼 다양한 집계 함수를 제공하고 있습니다. 따라서 이러한 테이블 형태의 데이터를 분석한다면 pandas는 언제나 핵심 도구로 활용됩니다.
사용법은 간단합니다. numpy array 혹은 리스트를 마치 딕셔너리 생성하듯 data에 넣고, pd.DataFrame() 함수로 감싸주면 됩니다.
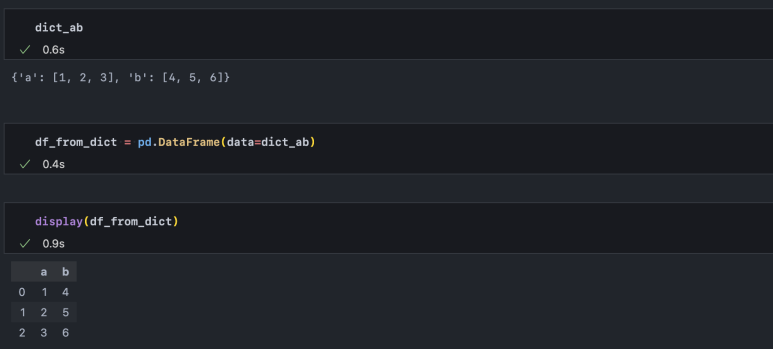
따라서 데이터 프레임은 dict 자료형으로도 간편하게 만들 수 있습니다.
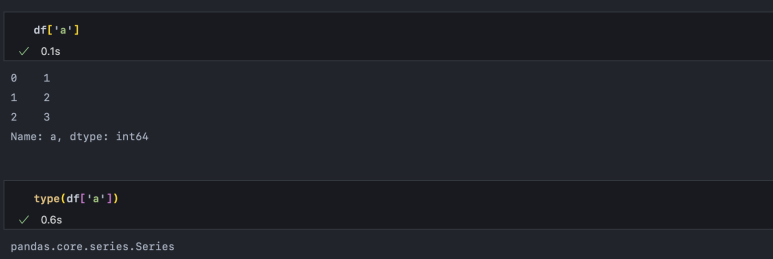
그리고 dict에서 '키'로 '값'을 인덱싱했던 것처럼 데이터 프레임은 행 인덱스(a, b)로 열 리스트를 조회할 수 있습니다. 이렇게 나오는 '값'이 바로 Series라는 자료형입니다.
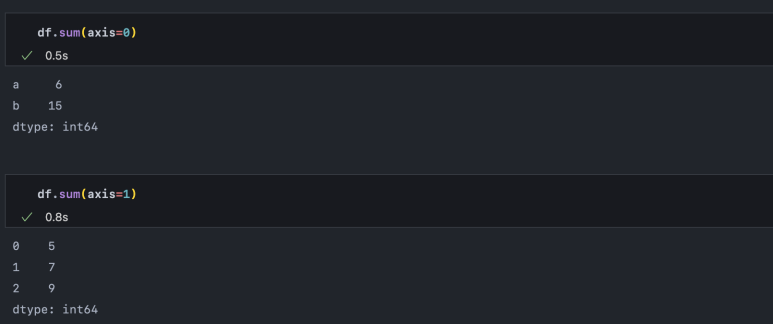
언급한 것처럼 데이터 프레임을 활용하면 매우 쉽게 데이터를 집계할 수 있습니다. 집계할 때는 항상 축을 생각해야 하는데, 행을 기준으로 집계하려면 axis=0, 열을 기준으로 집계하려면 axis=1을 사용합니다. 헷갈리면 실행 결과를 행 방향으로 만들고 싶은지, 열 방향으로 만들고 싶은지 떠올리면 수월합니다.
이렇게 아주 간단하게만 자료형에 대해서 알아봤습니다. 자료형은 가장 기초적이지만 실수가 매우 잦은 지점입니다. 특히 분석할 때 자료형을 유의 깊게 신경 쓰지 못해서 에러를 마주하는 경우가 많습니다. 그러나 분석을 수행해 보지 않은 상태에서 자료형을 너무 깊게 다루게 되면 암기과목처럼 되어버리니 앞으로 분석을 수행하면서, 다양한 함수를 사용해 보면서 자연스럽게 익혀나가도록 하겠습니다.