Step 1. 데이터 추출
1-1. 뉴스 기사 수집
먼저 investing.com에서 엔비디아 관련 기사를 수집한다. python requests 패키지를 사용해 post 방식으로 데이터를 가져올 것이다.
엔비디아 관련 뉴스 기사를 검색했을 때, 네트워크 XHR 탭에서 SearchInnerPage가 뉴스 데이터를 반환하는 것을 확인할 수 있다.

따라서 SearchInnerPage의 헤더 정보를 확인해 요청 데이터를 넣는 payload와 header를 만들어주고, requests.post() 함수를 통해 데이터를 받는다.
실습에서는 최근 300개의 뉴스 기사를 불러와 데이터 프레임으로 만들어줬다.
1-2. 주가 정보 수집
주가 데이터는 간단하게 yahoofinance 데이터를 가져오는 yfinance 패키지를 사용해 전체 기간 데이터를 불러온다. 여기서 Close(종가)만 사용할 것이다.
Step 2. 감성 분석
2-1. 감성 분석 모델 불러오기
우리는 사전학습된 감성 분석 모델을 사용할 것이다. 따라서 다양한 transformer 모델을 공유하는 플랫폼 Hugging face에서 적절한 모델을 찾아보자.
금융 관련 텍스트의 감성을 분류해주는 모델이 있다. 해당 모델을 사용하도록 한다.
Hugging Face를 통해 배포된 모델을 가져오는 가장 단순한 방법은 transformers 패키지의 pipeline 함수를 사용하는 것이다. 아래와 같이 코드를 작성해주면 감성 분류 모델이 각 뉴스 데이터에 대해 평가(분류) 한다.
senti_main은 뉴스 기사 헤더에 대한 분류 정보를 담고 있고, senti_sub는 뉴스 기사 텍스트 일부에 대한 분류 정보를 담고 있다.
감성 분류 모델은 positive, negative, neutral 3가지 감성으로 분류한다. 또한 각각의 평가(분류)에 대한 확신도(정확도)를 의미하는 score도 위와 같이 가져올 수 있다.
모델을 통해 분류한 감성 정보를 기존 데이터와 합쳐주자.
여기서 date 컬럼은 시간 정보를 담고 있으니 시계열 분석을 위해 인덱스로 저장해 준다.
title(뉴스 기사 제목)과 content(뉴스 기사 본문 일부)는 같은 기사에 대한 정보지만 텍스트 내용이 다르기 때문에 감성 모델이 다르게 평가할 수도 있다. 그러나 뉴스 기사 제목이 내용을 대표하므로 어조나 분위기가 유사할 것이라 짐작할 수 있고, 따라서 분류 결과의 차이가 너무 크면 모델을 신뢰하기 어렵다. title과 content에 대한 감성 분석 결과를 시각화해보자.
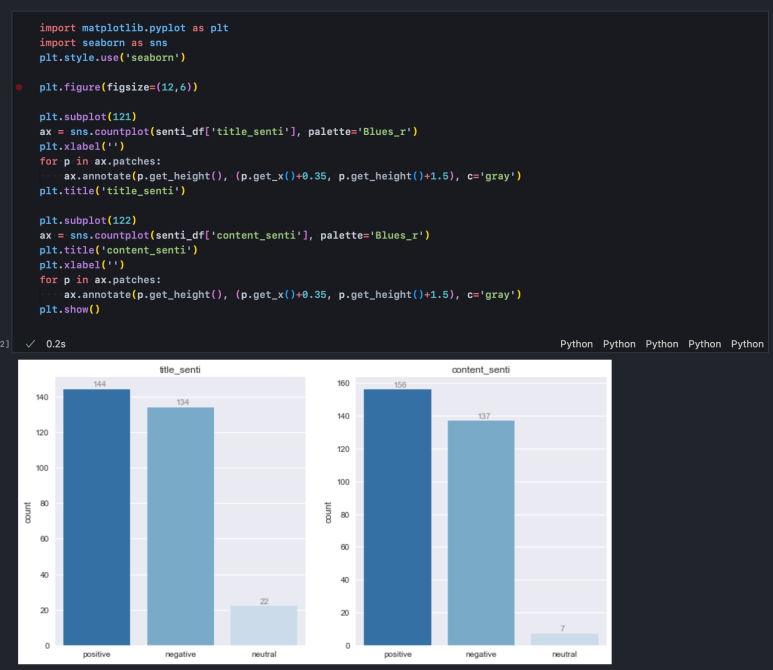
다행히 금융 텍스트가 잘 학습된 모델이라 우리가 가진 데이터도 비슷한 비중으로 분류해내고 있다.
특히 title에 대한 분류가 중립 감성(neutral) 비중이 높은 것을 보아 title 만으로 감성을 분류할 수 없는 케이스가 있고, content까지 확인했을 때 더 정확히 분류된다는 것을 확인할 수 있다. 따라서 우리는 title과 content 분류 결과를 모두 활용해 새로운 감성 score 값을 만들 것이다.
2-2. 감성 계량화
positive는 3점, neutral은 2점, negative는 1점으로 하고 확신도(score)를 곱해줄 것이다. 이를 title과 content에 각각 적용하여 두 데이터를 산술평균하는 방식으로 감성을 계량화하겠다.
먼저 3가지 분류 유형을 수치형 데이터로 변환해주고 위에서 확인한 3가지 분류 빈도와 동일한지 확인한다.
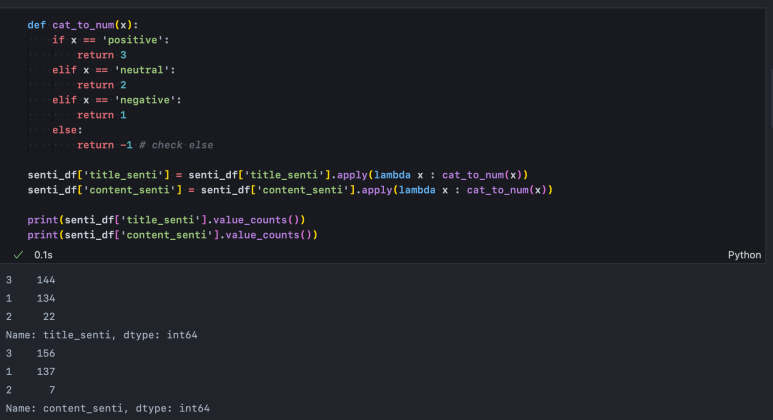
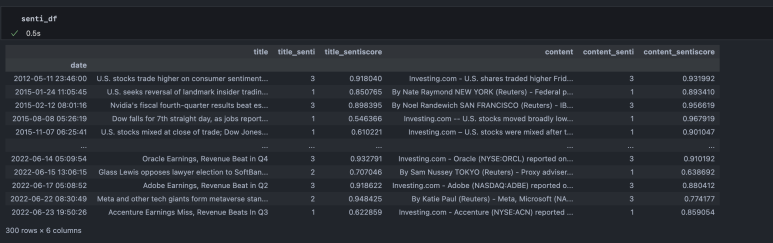
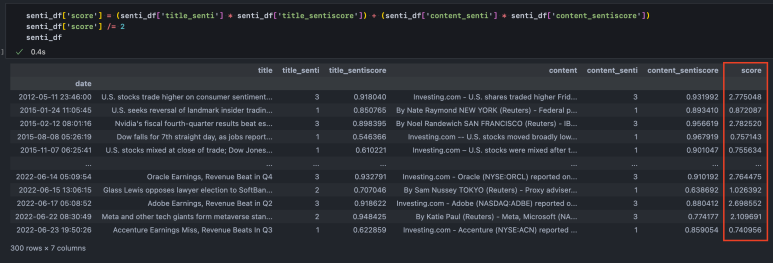
이제 앞서 정의한 방식으로 score를 계량화한다.
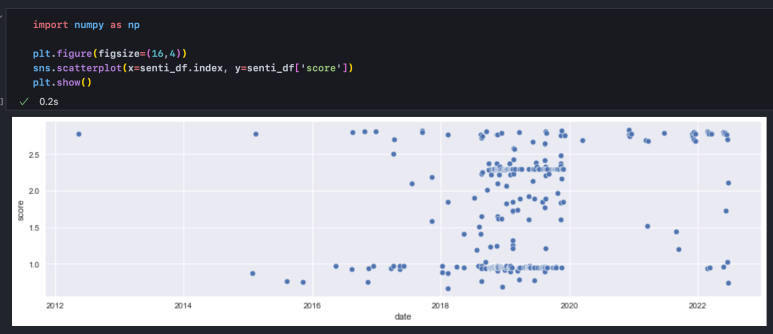
계량화한 score는 산점도를 통해 분포를 확인해 볼 수 있다.
Step 3. 주가 데이터 스케일링
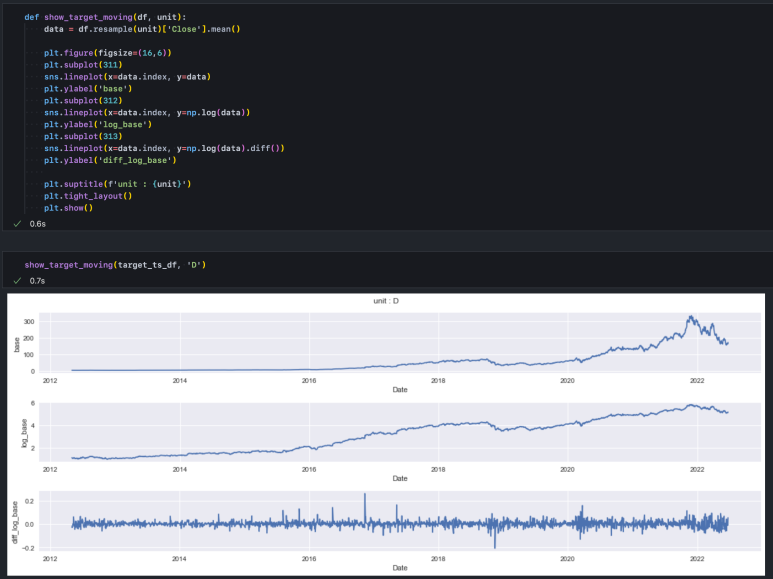
주가 데이터는 2가지 시계열상 특징이 있는데, 하나는 최근으로 올수록 스케일이 커진다는 점, 다른 하나는 자기상관성을 띤다는 점이다. 일반적으로 생존 편향이 있는 주가는 우상향하고, 엔비디아의 경우에도 그렇다.
최근(2022-6 기준)의 가격이 과거 대비 매우 크게 상승해 있기 때문에 과거의 1%보다 최근의 1%가 그 등락 폭이 훨씬 크다. 따라서 이러한 과거와 현재의 스케일 차이를 줄여주기 위해 log 변환을 해줄 필요가 있다.
또한, 오늘의 가격정보는 전날 가격 정보와 가장 가깝고 상관계수가 매우 높다. 시계열 데이터 분석은 정상성 확보를 위해 각 시점 간 데이터가 가능한 서로 독립이 되도록 해야 한다. 따라서 자기상관성을 제거하기 위해 log 변환된 데이터에 차분까지 실행해 줄 것이다.
먼저 주가 데이터는 전체 기간에 대해 가져왔기 때문에 뉴스 기사 데이터가 있는 시점만 추출한다.
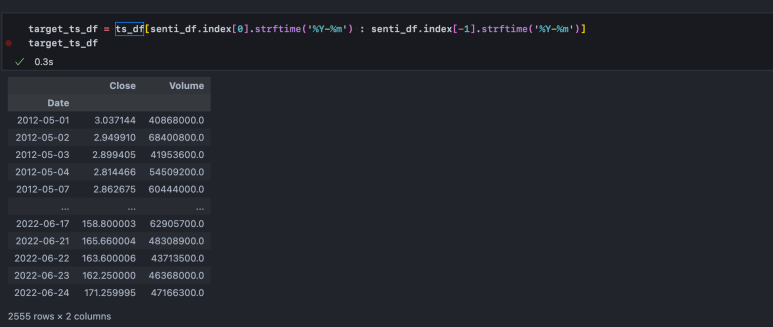
다음으로 기본 주가 데이터, log 변환된 데이터, log 변환 후 차분한 데이터를 확인해 본다.
Step 4. 상관 분석
우리는 주가에 대한 로그 차분 데이터와 계량화된 감성 데이터의 상관성을 분석할 것이다.
분석을 위해 두 데이터를 한 번 더 스케일링해 주자. 각 데이터를 정규화(min-max-scaling) 하면 0에서 1사이로 데이터 구간을 맞춰줄 수 있다. 여기서 0.5를 빼주면 음/양 표현이 가능하다. 즉 데이터가 -0.5에서 0.5 사이에 들어오도록 해줌으로써 각 시점에 대해 스케일링된 상승, 하락 포지션을 확인할 수 있다.
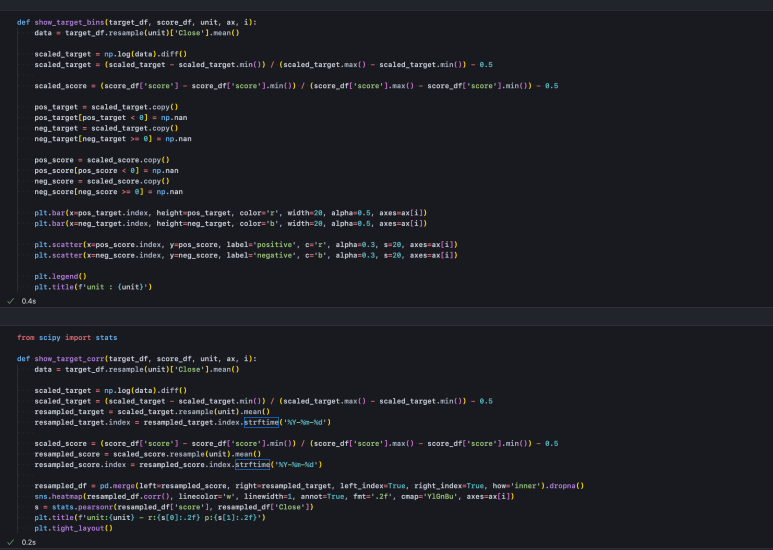
show_target_bins() 함수는 특정 기간(분기, 월, 주, 일) 별로 스케일링된 주가와 스케일링된 감성 score의 시계열 분포를 보여주고, show_target_corr() 함수는 그것의 상관 분포를 보여준다.
작성한 함수를 사용해 아래와 같이 각 기간별 시계열 분포, 상관 분포를 확인할 수 있다.
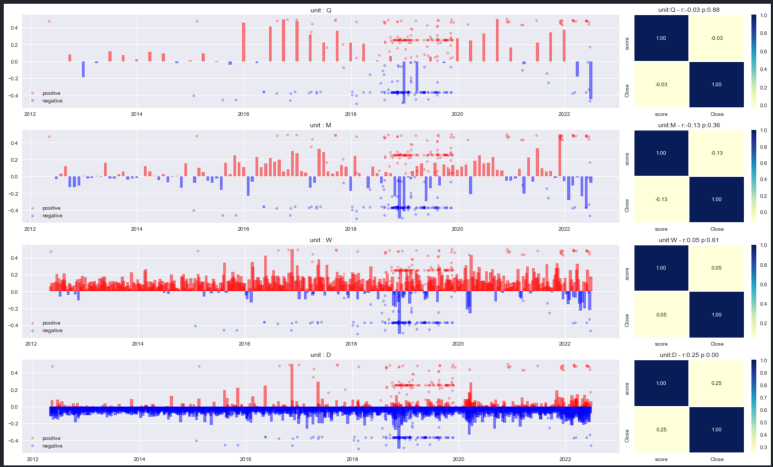
우측 상관 분포 표 타이틀에는 뉴스 기사에 대한 감성 스코어(scaled)와 각 기간(분기, 월, 주, 일) 별 주가(scaled)의 피어슨 상관 검정 결괏값을 표기했다. r은 상관계수, p는 p-value를 의미한다.
결론적으로 뉴스 기사는 유일하게 일별 주가와 유의한 수준으로 상관성이 있었으며 상관계수는 0.25로 높지 않은 수준이다. 만약 뉴스 기사가 나온 정확한 시점에 대해 분 혹은 시간별 주가 상관성을 구한다면 일별 주가 상관계수보다 더 높을 것으로 예상할 수 있다.
또한, 현재 수집된 뉴스 기사는 엔비디아를 검색했을 때 나오는 기사들이지만 엔비디아 외 다른 기업들에 대한 내용도 다수 포함되어 있다. 그럼에도 불구하고 '늘어진 시간 정보'로도 0.25만큼의 상관계수를 확인할 수 있었다. 따라서 엔비디아만 다루는 기사를 필터링하여 감성 스코어에 대한 분, 초 단위 인과성 검정을 시도한다면 선행지표로서의 유의성을 확인해 볼 수 있겠다.