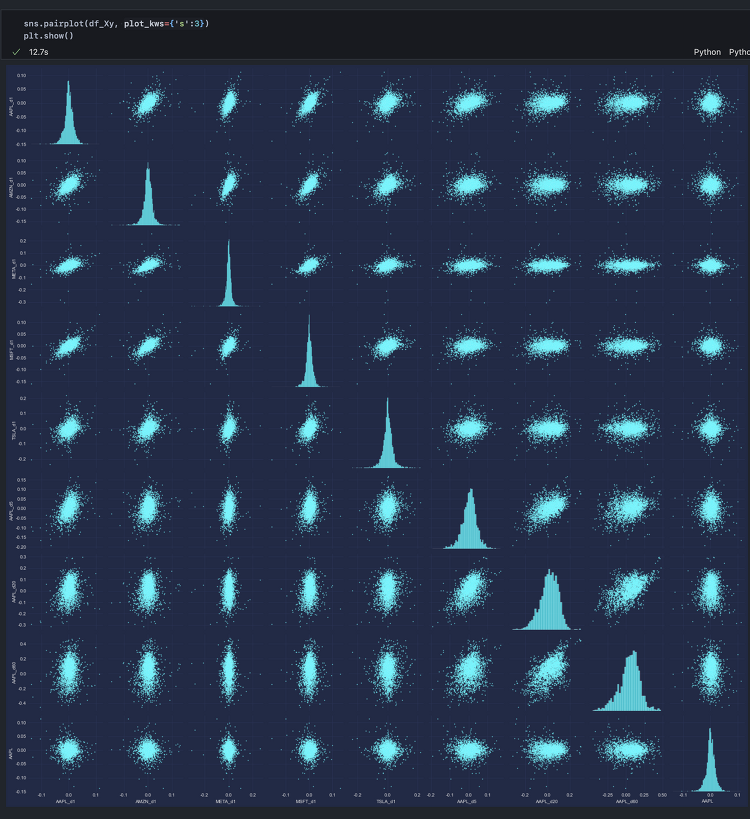
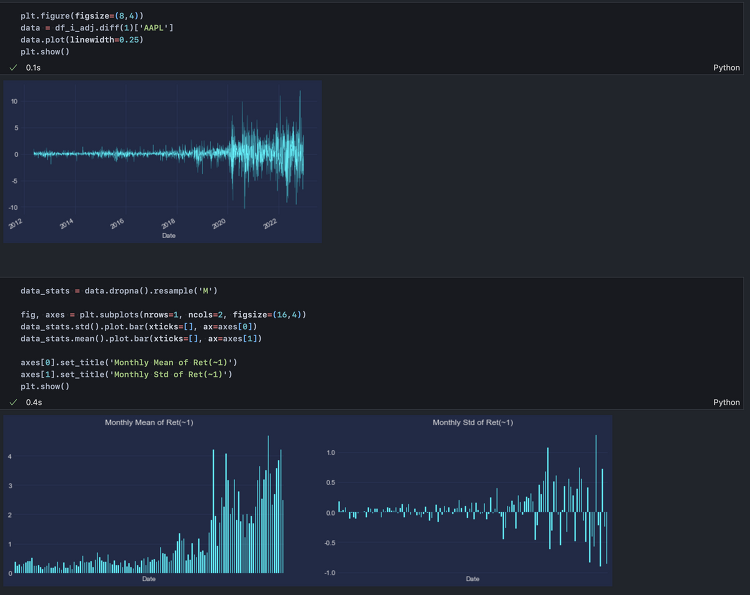
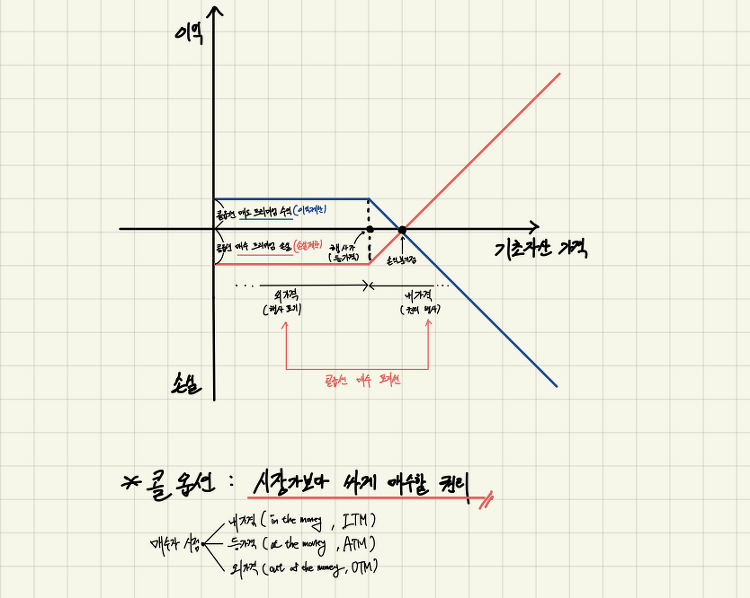
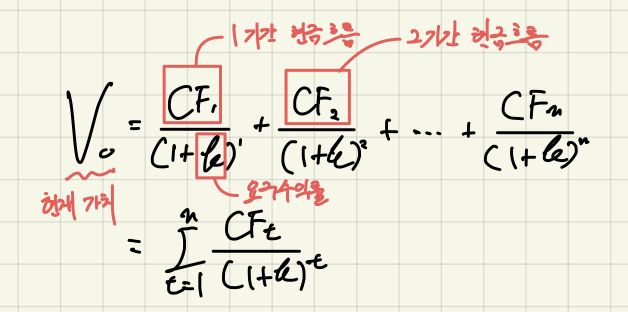
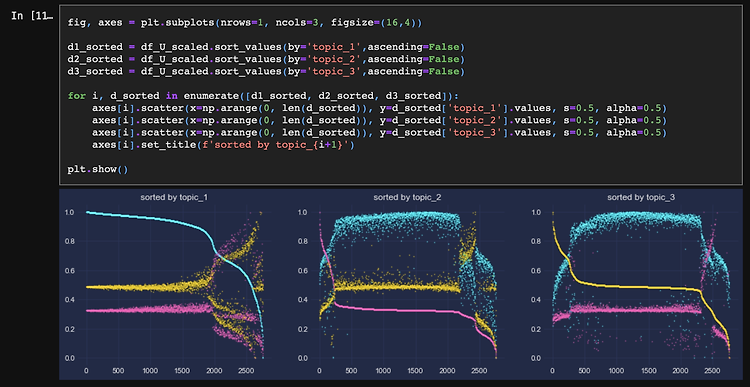
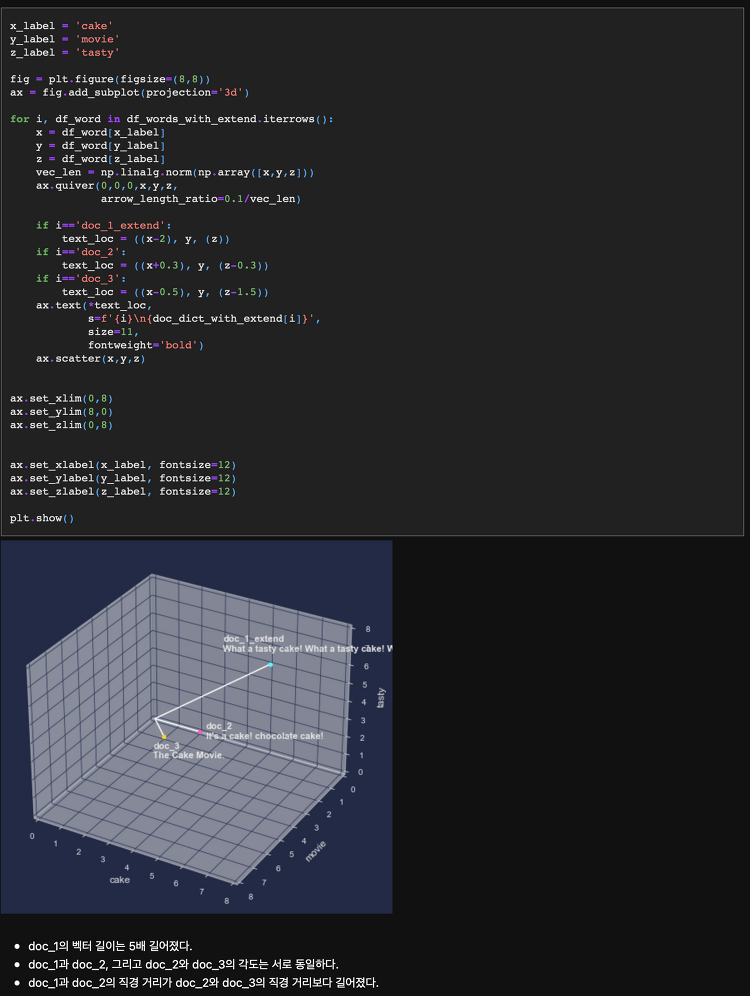
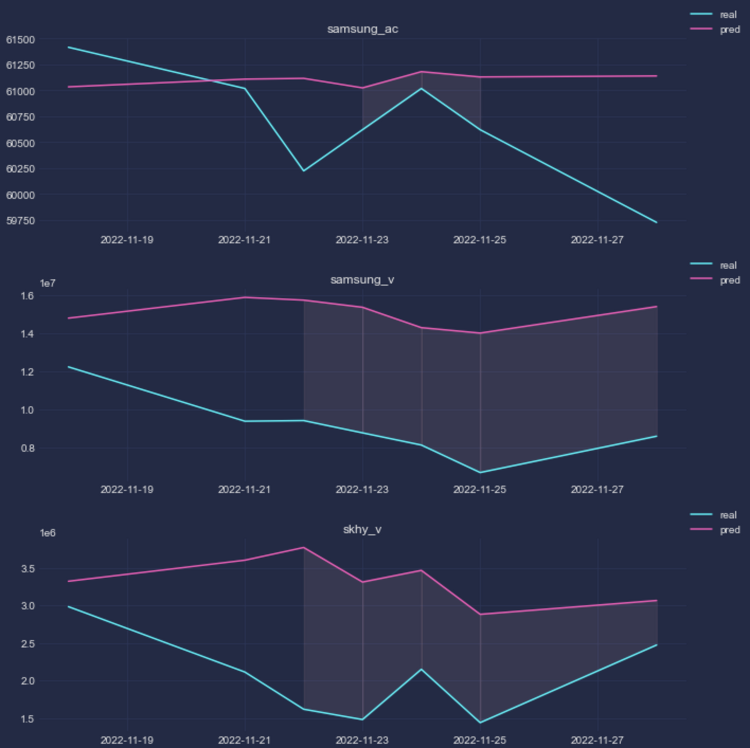
본격적으로 모델링을 수행하기 전에 변수간 상관관계가 어떤지, 예측변수의 정상성이 확보되었는지 확인할 필요가 있다. 특정 설명변수가 예측변수와 상관관계가 강하거나 특정 설명변수 간 상관관계가 강하다면 해당 변수를 유심히 살펴야 한다. 전자의 경우 예측변수에 후행하는 것은 아닌지, 후자의 경우 동일한 외생변수를 갖거나 둘 사이에 상호 인과성이 존재하는 것은 아닌지 등을 확인하고, 해당 변수를 소거하거나 집계를 통해 시점 혹은 분포를 변환해줘야 한다. 또한, 예측변수 내에 설명변수들로 하여금 예측변수를 추정하기 어렵도록 하는 특정 분포(추세, 계절성)의 존재 여부 역시 확인해야 한다. 예측변수 자체가 시간에 따라 그 분포(평균, 표준편차)를 달리한다면 단일변수를 통한 회귀분석은 물론 다중변수 모델링은 제대로 ..