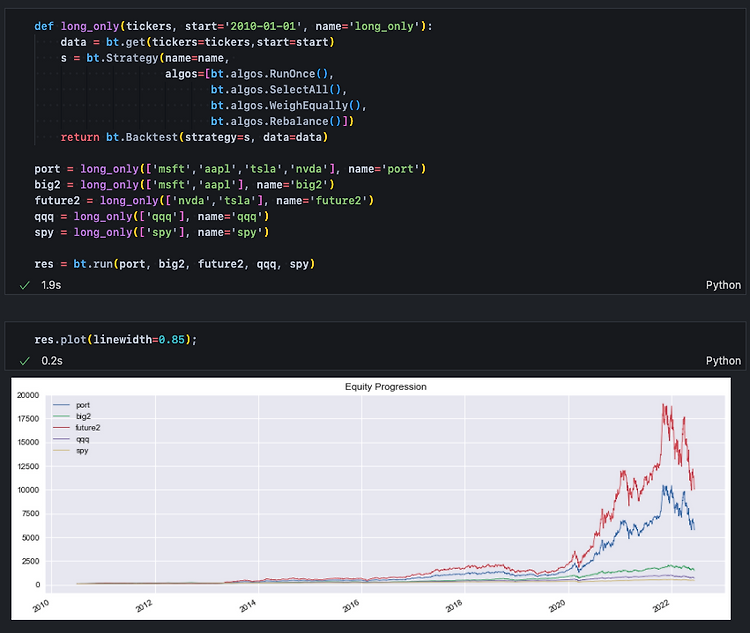
GridSearchCV reference : sklearn.model_selection.GridSearchCV(scikit-learn.org) 모형최적화, 데이터사이언스스쿨 [Chapter 4. 분류] 랜덤포레스트(Random Forest) 머신러닝 모델의 하이퍼파라미터를 조정하는 일은 매우 까다롭다. 아주 미묘한 파라미터 값 변화가 모델의 성능을 좌우하고, 모델마다 다양한 파라미터들이 유기적으로 얽혀있기 때문이다. GridSearchCV를 통하면 다양한 하이퍼파라미터 값을 미리 입력하고, 최적의 값과 해당 값으로 표현된 모델 정확도를 돌려받을 수 있다. from sklearn.model_selection import GridSearchCV params = {'n_estimators' : [10, 100..