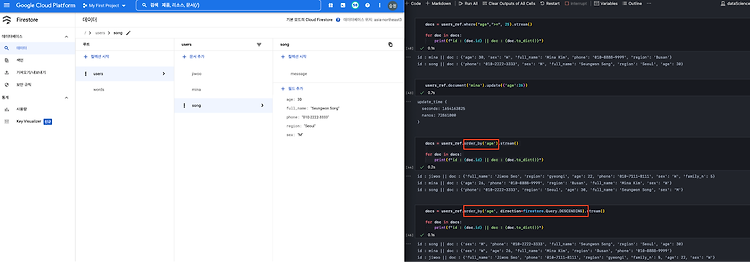
df.ffill() reference: pandas.DataFrame.ffill(pandas.pydata.org) Python pandas - 결측값 채우기 ... Python | Pandas dataframe.ffill() Pandas DataFrame ffill() Method 머신러닝 모델은 결측치가 존재하는 데이터프레임을 받아들이지 못한다. 따라서 데이터 전처리 과정에서는 반드시 NaN 값을 체크하고 해당 결측치를 특정 값으로 대체하거나 해당 결측치가 포함된 열 혹은 행을 제거해야 한다. 그러나 열 혹은 행을 제거한다면 중요한 데이터 소스를 잃어버리게 된다. 이를 감수할 만큼 해당 데이터 열 혹은 행이 유의미하지 않다면 무관하나 유의미하다면 제거하기보다 새로운 값으로 대체하는 것이 좋겠다. 결측치..