데이터 파이프라인 구축 (1)에서 csv 파일의 텍스트 전처리가 필요했다. 해당 부분부터 이어서 kibana 대시보드 작업까지 진행한다.
지난 글에서 작성했지만, 작업환경과 파이프라인 flow도 다시 보자.
"""
작업 환경:
- Macbook Pro 2019 - i9, 16GB
- GCP 가상 머신 4대 할당(e2-small 3대 + e2-medium 1대)
- 가상 머신 1대에 클러스터 1개 배치(클러스터당 노드도 1개씩)
- filebeat 설치(Local)
- logstash 설치(Local)
- elastic search 설치(e2-small 3개 각각 설치)
- kibana 설치(e2-medium 1대에 설치)
데이터:
서울시 상권 추정 매출(서울시 열린 데이터 광장 제공)
구축할 데이터 파이프라인 Flow:
- Beats : 데이터 수집
- Logstash : 데이터 전처리(필터링)
- Elasticsearch : 데이터 저장 및 관리
- Kibana : 데이터 시각화
"""
Step 6. (이어서) csv 파일 수정하기
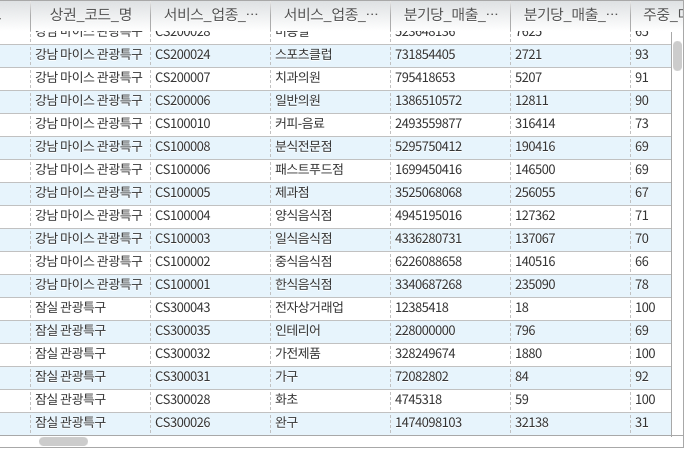
먼저, csv의 큰 따옴표 제거한다. 시스템상 특수문자마다 역슬래시 처리가 된 채로 전달되어야 텍스트를 정상적으로 읽을 수 있기 때문에 beats가 역슬래시를 포함한 텍스트를 logstash의 input값으로 전달하게 된다. 따라서 역슬래시가 포함되지 않도록 vim을 사용해 특수문자(")를 지워준다.
Step 7. Logstash filter 추가하기 - 데이터 타입 지정
다음으로, int형을 지정해준다. default로 문자열 형태로 입력되는데 이러면 대소 비교가 되지 않는다. 따라서 logstash filter를 활용해 int 변환 후 elastic search로 보내준다.
Step 8. Kibana Index pattern 설정하기
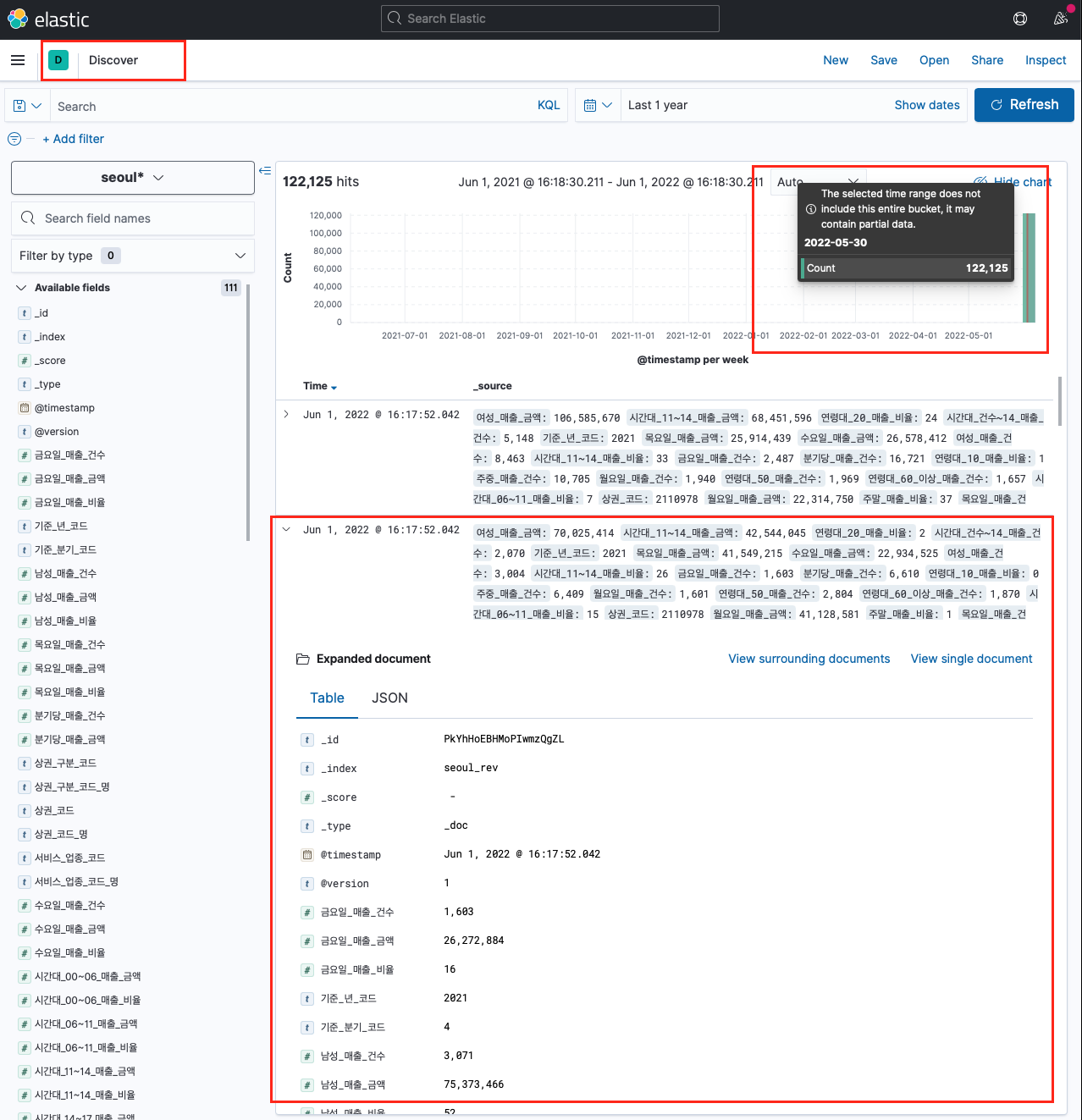
이제 키바나 대시보드에 올린건데, 그전에 Index pattern을 생성해줘야 한다. 카바나에서 각각의 field와 해당 값을 인식하게 해 준다.
Index pattern을 정상적으로 설정했다면 Discover 탭에서 timestamp에 따라 데이터가 쌓이는 모습을 볼 수 있다. 지금은 데이터가 약 12만 건이고, 5월 30일 기준으로 한 번에 넣었기 때문에 이렇게 데이터가 몰려있다.
Step 9. Kibana Dashboard 생성하기
이제 Dashboard 탭에 들어가서 맘껏 패널을 생성하면 된다. 대시보드 내 각각의 화면 요소가 패널이고, 패널은 Create panel 버튼을 통해 생성할 수 있다.