Step 0. 실습 전 확인 사항
Elastic Stack은 Elastic Search를 중심으로 Beats, Logstash, Kibana를 활용해 데이터파이프를 구축하는 일련의 설계 방식이다. 이번 실습은 아래의 순서로 진행된다.
- 서울시 상권 추정 매출 데이터를 Beats로 읽어들여서,
- Logstash로 보내 문자열 처리를 거친 다음,
- Elastic search로 적재하고,
- Kibana로 대시보드를 그려보는 것
먼저, 실습 전에 나의 작업 환경은 아래와 같다. 동일하게 세팅할 필요는 없으며, 클라우드를 사용하지 않고 개인 로컬 환경에서도 충분히 실습이 가능하다.
작업 환경:
- Macbook Pro 2019 - i9, 16GB
- GCP 가상 머신 4대 할당(e2-small 3대 + e2-medium 1대)
- 가상 머신 1대에 클러스터 1개 배치(클러스터당 노드도 1개씩)
- filebeat 설치(Local)
- logstash 설치(Local)
- elastic search 설치(e2-small 3개 각각 설치)
- kibana 설치(e2-medium 1대에 설치)
그리고. 우리가 사용할 데이터는 다음과 같다.
데이터:
서울시 상권 추정 매출(서울시 열린 데이터 광장 제공)

Elastic Stack의 각 구성요소별 역할을 다시 확인하고 넘어가자.
구축할 데이터 파이프라인:
- Beats : 데이터 수집
- Logstash : 데이터 전처리(필터링)
- Elasticsearch : 데이터 저장 및 관리
- Kibana : 데이터 시각화
나의 작업 환경도 참고할 수 있도록 캡쳐해보았다.
GCP VM에 접속한 모습 :
Step 1. beats -> logstash 연결하기
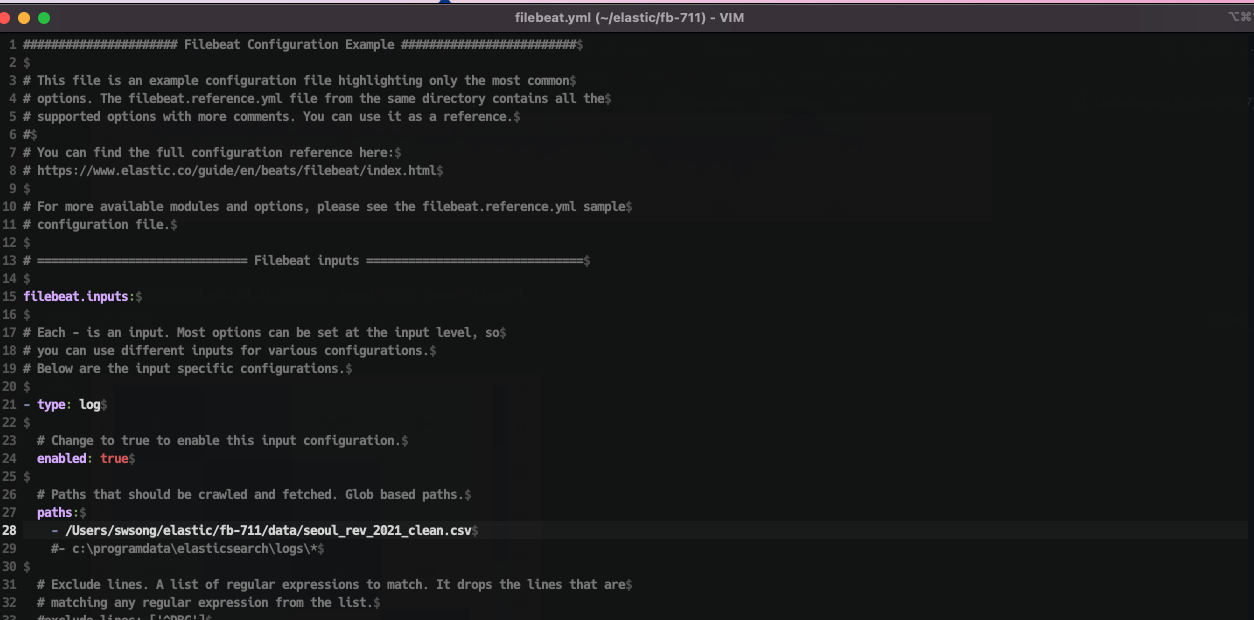
beats를 정상적으로 설치했다면, filebeat.yml 파일이 있을 것이다.
파일을 vim이나 다른 텍스트 에디터로 열어서 output.logstash 부분의 hosts가 logstash를 가리키도록 수정해주자. logstash의 포트 번호를 따로 건드리지 않았다면 기본적으로 5044번으로 설정되어 있다. 그리고 logstash 폴더 내에 conf 파일을 생성해서 input과 output을 아래와 같이 설정해주자. input으로는 beats가 5044번 포트로 보내줄 데이터를 받고, output으로는 기본 출력(stdout)과 elastic search 2개 방향으로 보내준다.
stdout 부분의 codec 은 출력 형태를 말한다. rubydebug는 json 형태로 출력하라는 의미다. elasticsearch 부분의 host는 beats 설정과 마찬가지로 elasticsearch의 외부 호스팅 주소와 포트 번호를 설정해주면 된다. 내 경우는 gcp 가상 머신을 사용하기 때문에 해당 머신의 주소를 설정해줬다. index는 elasticsearch 자료구조에서 해당 문서를 조회할 수 있도록 하는 이름이다. 데이터 파일 이름이라 생각하면 된다.
모두 설정했다면 "$/bin/logstash -f conf파일명" 명령을 통해 logstash를 실행해주자.
logstash가 잘 실행되었다면 위와 같이 Pipeline running과 함께 5044 포트번호가 표시된다. 이제 beats와 elasticsearch의 중간다리를 세운 것이다.
Step 2. raw data -> Beats 연결하기
이제 다시 filebeat.yml 파일을 열어서 filebeat.inputs를 설정해준다. logstash의 input이 beats였다면, beats의 input은 원본 데이터이다. 우리는 실시간 데이터를 사용하지 않기 때문에 데이터가 들어 있는 파일 경로를 설정해주면 된다.
Step 3. raw data -> Beats -> Logstash -> Stdout 출력 확인하기
다음으로 beats를 설치한 루트 폴더에서 "$./filebeat -e -c filebeat.yml" 명령을 실행하면 아래와 같이 logstash로 데이터가 들어가고, 데이터 로그가 stdout으로 출력된다.
beats가 파일 읽어서 데이터 전송하는 모습 :
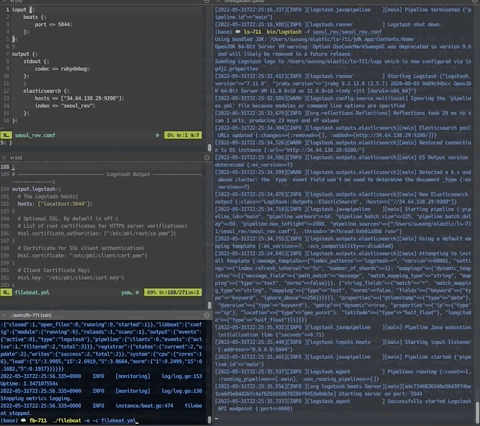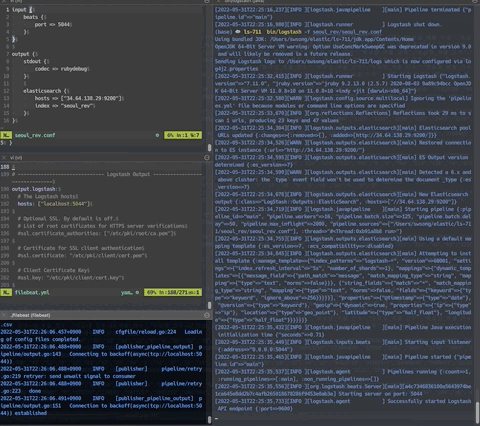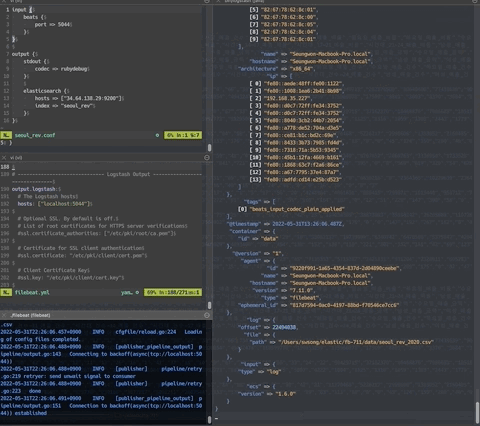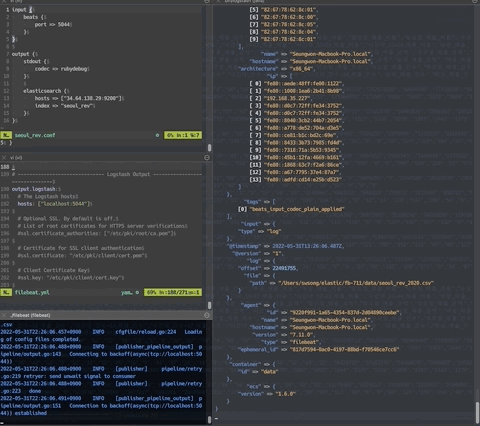
그런데 csv 파일을 한 줄씩 읽어서 전송하다보니 컬럼 명과 매치되지 않은 원천 데이터가 그대로 입력된다.
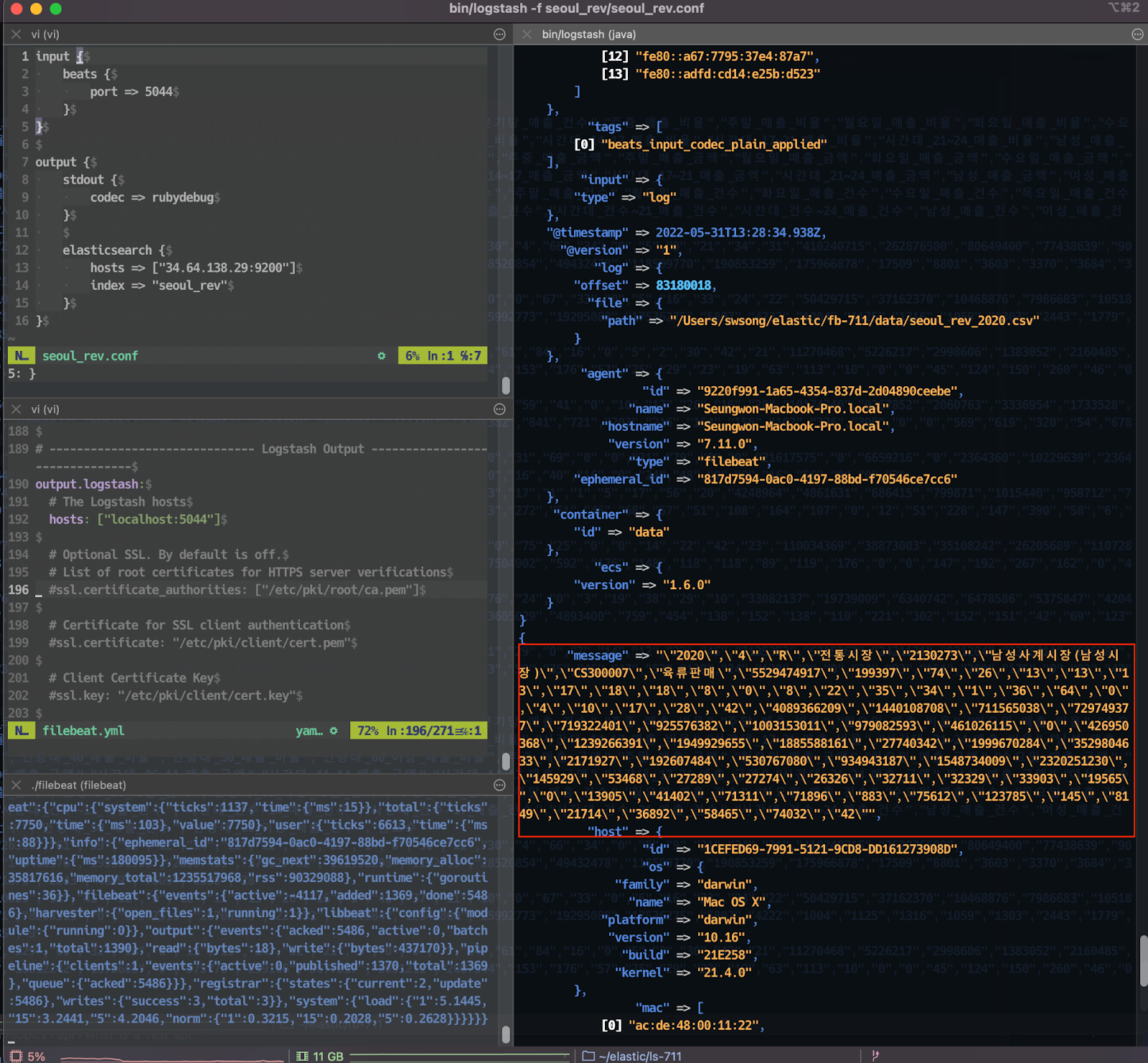
Step 4. Elastic Search 검색하기
이렇게 입력되면 elastic search로 "일반의원"이라 검색했을 때, 매출 정보를 파악할 수 없다. 아래 화면은 kibana를 실행하면 띄울 수 있는 브라우저다. 여기서 간단하게 elastic search 명령어를 사용해볼 수 있다. 브라우저에 접속해 Dev Tools에 들어가서 GET∈dex∠search 쿼리를 날려주면 되는데, message에 입력한 키워드와 매칭되는 텍스트를 불러올 수 있다.
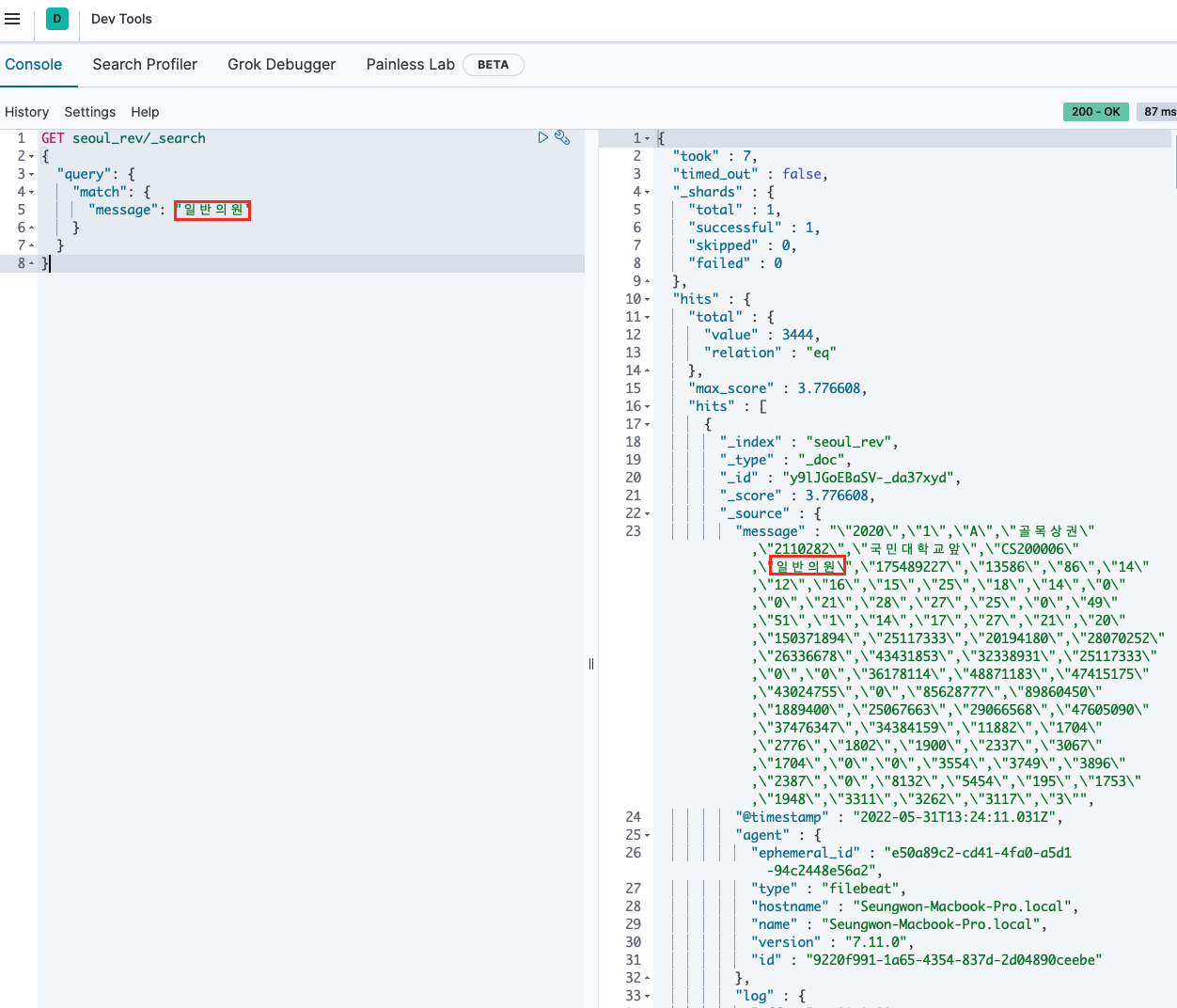
Step 5. Logstash filter 설정하고 파이프라인 다시 세우기
무튼, 이렇게 역슬래시도 들어가고 제대로 데이터 분리가 되지 않은 원본 형태이기 때문에 데이터 소스를 그대로 사용하기에는 적절하지 않은 것 같다. elastic search나 kibana를 사용할 때에는 최대한 메모리 자원을 아껴서 방대한 데이터를 효율적으로 활용하는 것이 좋다. 따라서 Logstash에 input, output 사이에 filter를 설정해준다.
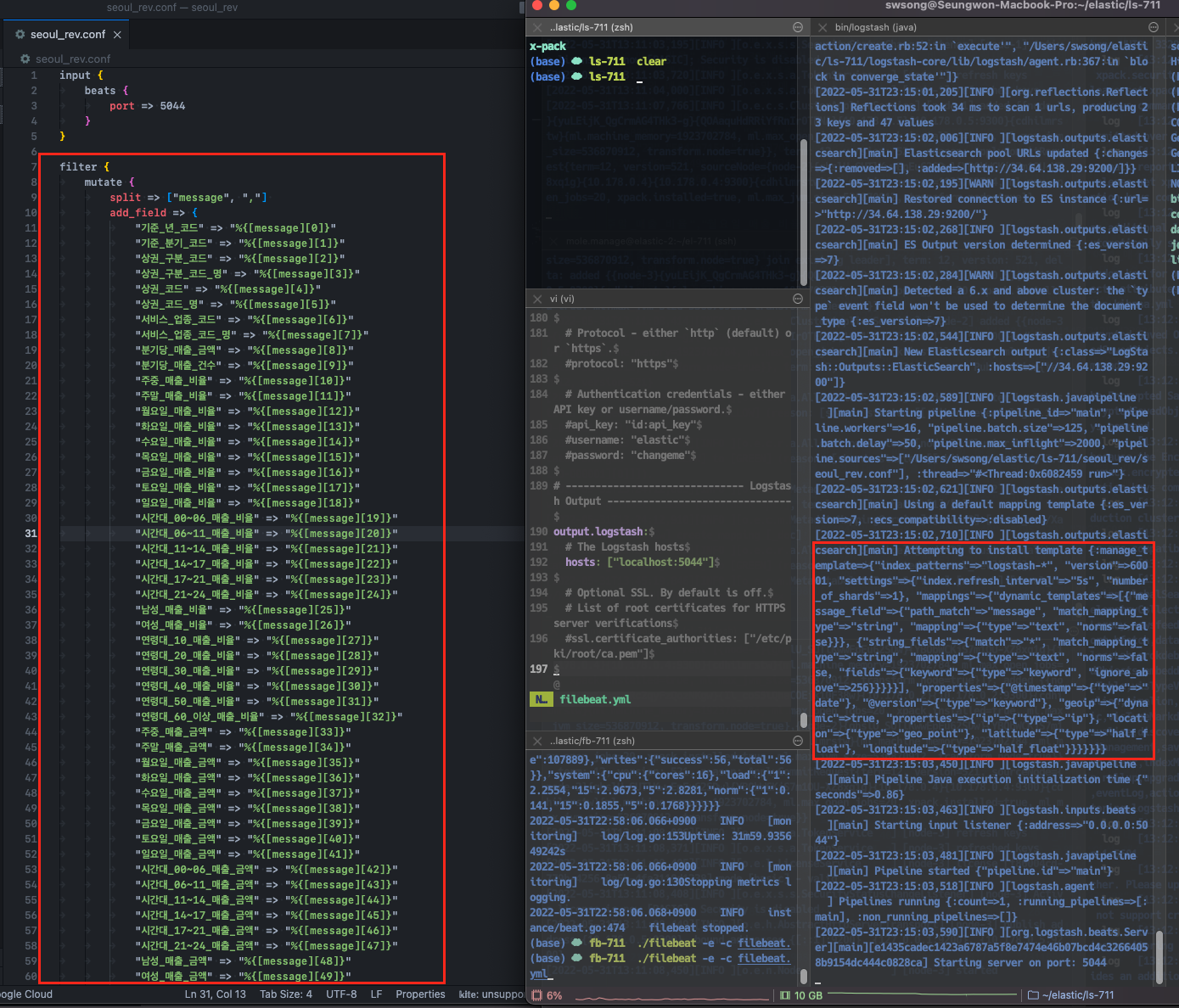
다시 beats를 실행해 데이터를 입력한다. 이때, stdout codec은 dots로 설정해서 데이터가 들어가는 상황만 모니터링할 수 있도록 한다.
이제 다시 elastic search로 입력된 데이터를 확인해보자.
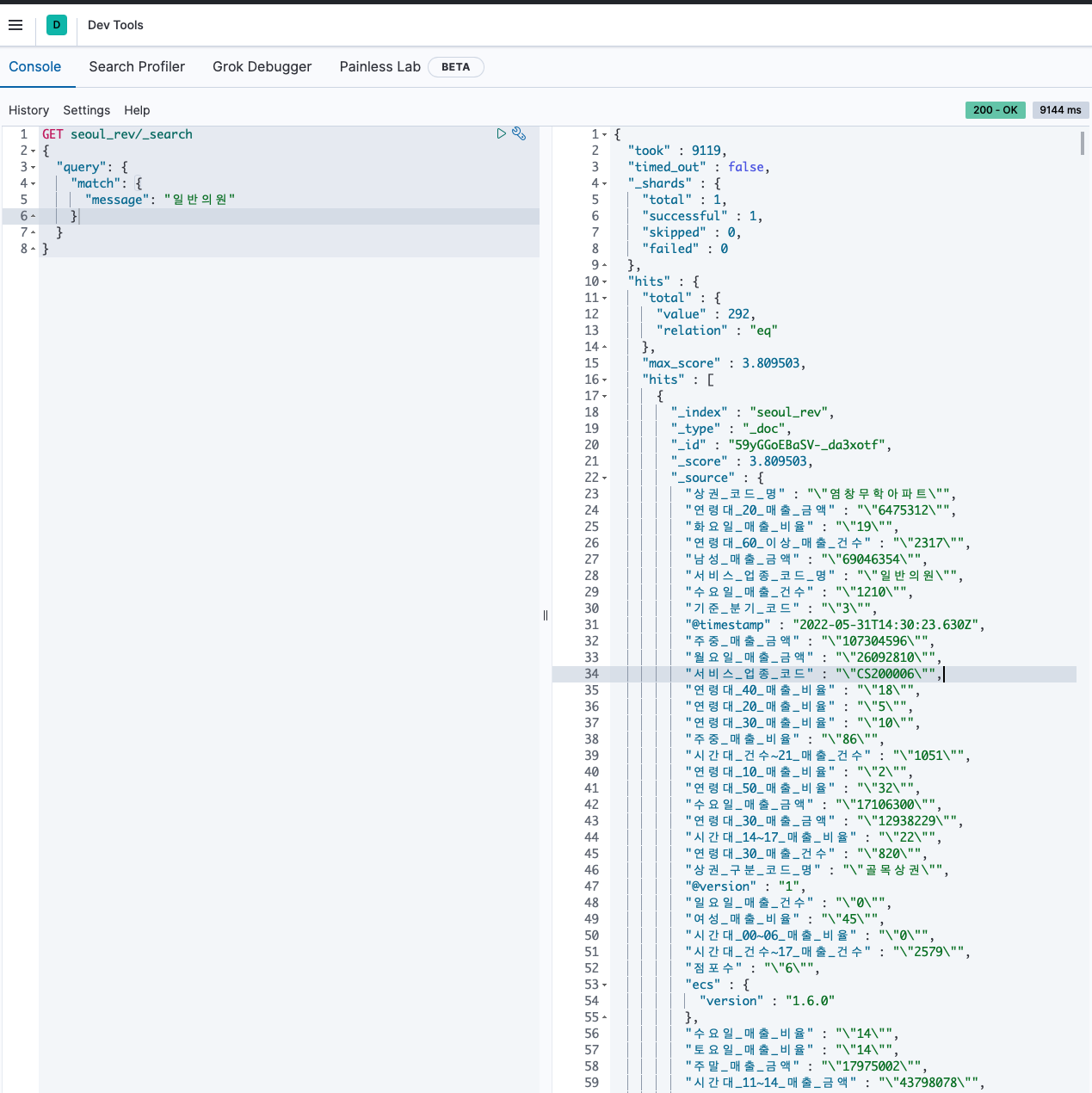
데이터는 잘 분리되어 들어가는데, 좀 이상하다. 역슬래시도 여전히 포함되어 있고, 전부 string으로 입력됐다. 키바나로 모니터링하려면 매출 관련 수치는 모두 정수 혹은 실수형으로 입력되어야 하기 때문에 해당 부분도 처리해야 한다. (다음에 이어서..)