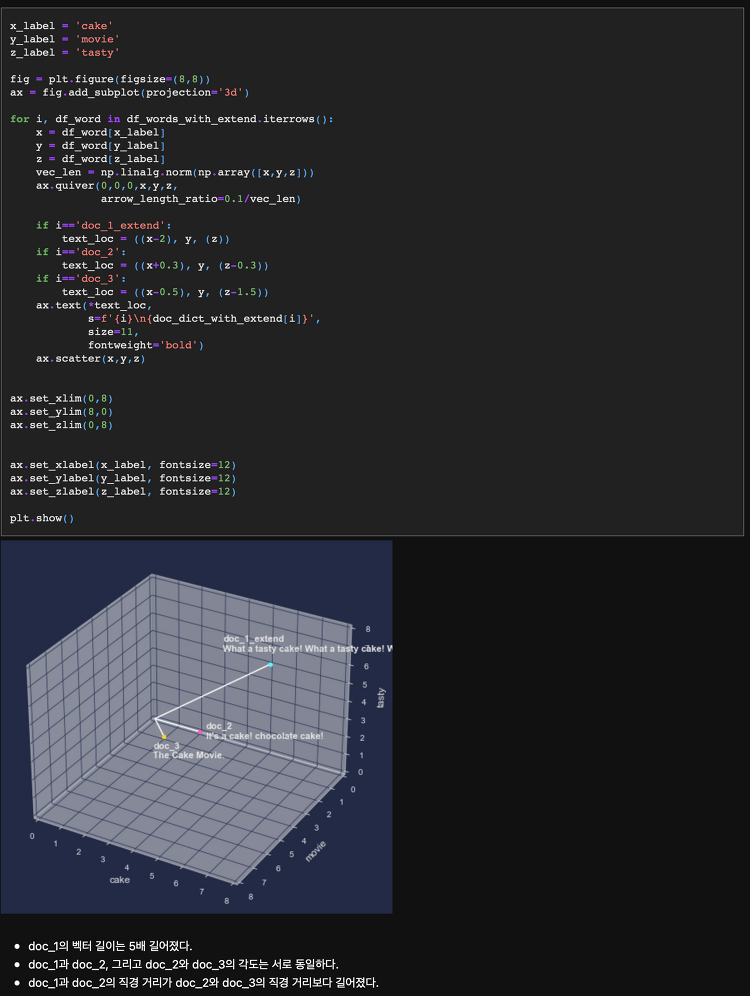
Step 1. 문장의 유사도를 구하는 방법 두 문서의 유사성은 어떻게 측정할 수 있을까? 문장의 길이? 아니면 주어, 동사, 목적어 등의 문법 구조? 그것보다는 얼마나 공통 '단어'를 많이 포함하고 있는가? 가 더 합리적으로 보인다. 실제로 수많은 전통적인 텍스트마이닝 방법론들은 이러한 단어 기반 유사도 측정 방식을 따르며, 현재 딥러닝, AI 시대에도 역시 문장 구조와 속성을 분석할 때 단어는 핵심 요소다. 이렇게 단어를 기준으로 문장 유사도를 구하기 위해서는 단어를 숫자로 변환해 줄 필요가 있다. 즉, 유사도 혹은 거리를 수학적으로 계산하기 위해 문장을 일종의 좌표평면 상에 놓을 수 있어야 하고 문장이 좌표평면에 놓이기 위해서는 문장을 구성하고 있는 단어들을 스칼라 혹은 벡터값으로 변환해줘야 하는 것..