딥러닝 신경망 모형이 언제나 이길까?
본 분석은 머신러닝 모델의 예측 성능을 비교함으로써 딥러닝(다층 신경망)이 언제나 만능일 수 없음을 검증하고자 한다. 물론 신경망의 경우 Hyper-parameter 튜닝 및 딥러닝에 최적화된 Feature Engineering을 통해 미세한 성능 개선이 가능하지만, 단순 이진 분류의 경우에 딥러닝보다 빠른 속도와 우수한 성능을 보여주는 가벼운 머신러닝 모델을 쉽게 찾을 수 있음을 보여주기 위함이다.
그럼, 자연스럽게 가설을 하나 설정해두고 분석을 진행하도록 하겠다.
1. 가설 설정 및 데이터 분포 확인
- 귀무가설 : 동일한 데이터로 동일한 정규화 과정을 거쳤을 때 머신러닝 모델 중 신경망 알고리즘의 성능이 가장 우수하다.
- 연구가설 : 동일한 데이터로 동일한 정규화 과정을 거쳤을 때 머신러닝 모델 중 신경망 알고리즘의 성능이 가장 우수한 것은 아니다.
데이터는 UCI Machine Learning Repository의 Adult Data Set을 사용한다. 해당 데이터는 소득 예측을 위한 정보를 담고 있으며, 연 $ 50K 이하 혹은 초과 케이스에 대한 label(y)를 함께 제공하고 있다.
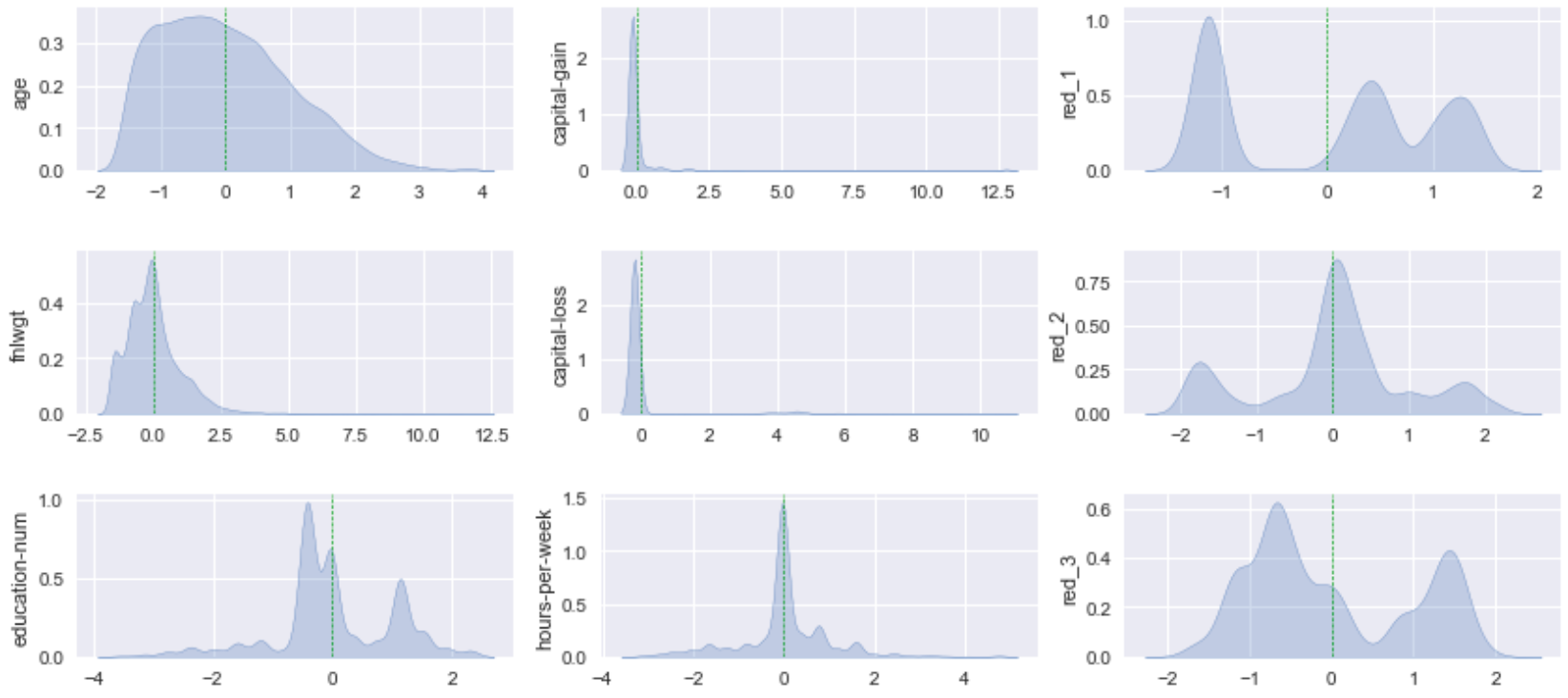
각 컬럼은 범주형, 수치형 데이터가 섞여 있으며 각각의 분포는 아래와 같다.

2. 데이터 전처리 과정 확인
머신러닝의 경우 모든 학습 데이터가 수치로 입력되어야 하므로 One-Hot-Encoding 방식을 사용해 범주형 데이터를 모두 변환해주었고, 이때 데이터가 희소해지는 현상(One-Hot-Encoding시 데이터는 0과 1로 채워지며 0이 1에 비해 많은 공간을 차지하므로 머신러닝의 학습이 원활하지 못하게 됨)에 대응하여 차원 축소(PCA, Principal Component Analysis)도 함께 수행해주었다. 과정마다의 결과물을 확인하고 넘어가자.
이렇게 범주형 변수를 수치화한 다음 머신러닝 모델에 바로 입력하지 않고 정규화를 거치는 것이 좋다. 데이터의 평균 및 분산이 컬럼마다 다르게 되면 수치상 평균이 큰 특정 칼럼에 대한 영향이 다른 칼럼들의 분포를 상쇄시키기 때문이다. 범주형, 수치형 변수를 모두 정규화(평균 0, 표준편차 1)하고, 분포를 확인하면 다음과 같다.
3. 모델간 예측 성능 비교
해당 데이터에 대해 총 5개의 머신러닝 모델로 예측을 수행했다.
3-1. Logistic Regression
precision recall f1-score support
0 0.87 0.93 0.90 6171
1 0.72 0.56 0.63 1970
accuracy 0.84 8141
macro avg 0.79 0.74 0.76 8141
weighted avg 0.83 0.84 0.83 8141
---
Precision
- 연소득 $50,000 이하로 예측한 케이스의 87% 일치
- 연소득 $50,000 초과로 예측한 케이스의 72% 일치
Recall
- 실제 연소득 $50,000 이하 케이스 중 93% 정상 분류
- 실제 연소득 $50,000 초과 케이스 중 56% 정상 분류
데이터 불균형으로 연소득 $50,000에 대한 예측 성능이 더 우수3-2. Random Forest
precision recall f1-score support
0 0.89 0.93 0.91 6171
1 0.74 0.62 0.68 1970
accuracy 0.86 8141
macro avg 0.81 0.78 0.79 8141
weighted avg 0.85 0.86 0.85 8141
---
Precision
- 연소득 $50,000 이하로 예측한 케이스의 89% 일치
- 연소득 $50,000 초과로 예측한 케이스의 74% 일치
Recall
- 실제 연소득 $50,000 이하 케이스 중 93% 정상 분류
- 실제 연소득 $50,000 초과 케이스 중 62% 정상 분류
마찬가지로 데이터 불균형으로 연소득 $50,000에 대한 예측 성능이 더 우수하지만 Linear Model보다 부족한 데이터셋에 대한 예측력이 좋음3-3. XGBoost
precision recall f1-score support
0 0.89 0.94 0.91 6171
1 0.76 0.65 0.70 1970
accuracy 0.87 8141
macro avg 0.83 0.79 0.81 8141
weighted avg 0.86 0.87 0.86 8141
---
Precision
- 연소득 $50,000 이하로 예측한 케이스의 89% 일치
- 연소득 $50,000 초과로 예측한 케이스의 76% 일치
Recall
- 실제 연소득 $50,000 이하 케이스 중 94% 정상 분류
- 실제 연소득 $50,000 초과 케이스 중 65% 정상 분류
기본 배깅 방식에서 개선된 학습 알고리즘인 랜덤포레스트보다도 부스팅 알고리즘이 성능이 좋았음.3-4. LightGBM
precision recall f1-score support
0 0.89 0.94 0.91 6171
1 0.76 0.64 0.70 1970
accuracy 0.87 8141
macro avg 0.83 0.79 0.81 8141
weighted avg 0.86 0.87 0.86 8141
---
Precision
- 연소득 $50,000 이하로 예측한 케이스의 89% 일치
- 연소득 $50,000 초과로 예측한 케이스의 76% 일치
Recall
- 실제 연소득 $50,000 이하 케이스 중 94% 정상 분류
- 실제 연소득 $50,000 초과 케이스 중 64% 정상 분류
위에서 확인한 XGBoost와 매우 유사한 수치 확인. 하이퍼파라미터를 사용하지 않는다면 Boosting 계열간 큰 차이는 볼 수 없음3-5. Deep Learning
precision recall f1-score support
0 0.89 0.91 0.90 6171
1 0.70 0.63 0.67 1970
accuracy 0.85 8141
macro avg 0.79 0.77 0.78 8141
weighted avg 0.84 0.85 0.84 8141
---
Precision
- 연소득 $50,000 이하로 예측한 케이스의 89% 일치
- 연소득 $50,000 초과로 예측한 케이스의 70% 일치
Recall
- 실제 연소득 $50,000 이하 케이스 중 91% 정상 분류
- 실제 연소득 $50,000 초과 케이스 중 63% 정상 분류
Boosting 계열보다 정확도는 떨어지며 Logistic Regression보다 불균형 데이터셋을 잘 반영한다는 점에서 유리하지만, 큰 차이는 없었다.
4. 결론
모델간 성능 비교 결과 Gradient Boosting 계열의 알고리즘(XGBost, LightGBM)의 예측 정확도가 가장 좋았고, 속도를 고려했을 때, LightGBM이 가장 우수했다. 따라서 귀무가설을 기각하고 연구가설(동일한 데이터로 동일한 정규화 과정을 거쳤을 때 머신러닝 모델 중 신경망 알고리즘의 성능이 가장 우수한 것은 아니다)을 채택한다.
실제로 캐글 대회에서도 많은 분석가들이 부스팅 계열 알고리즘으로 빠르고 정확한 모델을 구현해내고 있고, 특히 모델의 연산 속도가 중요한 금융이나 보안 등의 주요 산업 분야에서 부스팅 모델을 선호하는 경향이 있다. 산업 현장에서는 엔지니어의 회고, 피드백 과정을 통한 책임이 중요하기 때문에 모델의 해석 가능성과 설명력이 모델 선택의 주요 기준 중 하나다. 이러한 점에서도 신경망 모형보다 부스팅 계열 알고리즘 혹은 랜덤 포레스트 같은 트리 모형이 신경망 보다 유리한 부분이 있다.
요즘은 여러 모델을 함께 비교 분석하는 AutoML 패키지가 잘 나와있기 때문에 무조건 딥러닝을 사용하는 것보다 다양한 모델을 비교분석하면서 장단을 따져보는 것이 좋겠다.
👉 분석 및 모델링에 사용된 파이썬 코드(주피터 노트북) 링크